Open Agent Leaderboard: por fin ya puedes comparar sistemas de agentes y no solo modelos
El Open Agent Leaderboard publicado el 18 de mayo de 2026 cambia la pregunta para builders: no basta con mirar el modelo; ahora toca medir costo, herramientas y arquitectura del agente completo.
Por qué importa
Esta nota se enfoca en la decisión práctica para builders: qué cambia, qué riesgo agrega y cómo aplicarlo sin romper operación.
Los builders llevamos meses cayendo en la misma trampa: elegir modelo con un benchmark y asumir que el agente completo heredara esa ventaja. El 18 de mayo de 2026, IBM Research publico en Hugging Face el Open Agent Leaderboard para romper justo esa confusion. La apuesta no es medir un LLM aislado, sino el sistema agentico completo: modelo, herramientas, memoria, planificacion, recuperacion y costo.
La idea suena obvia, pero llega en un momento útil. Hoy casi todos comparan agentes con titulares de benchmark de modelo. El nuevo leaderboard parte de otra premisa: dos agentes con el mismo modelo pueden rendir y costar muy distinto según la arquitectura que les pongas alrededor.
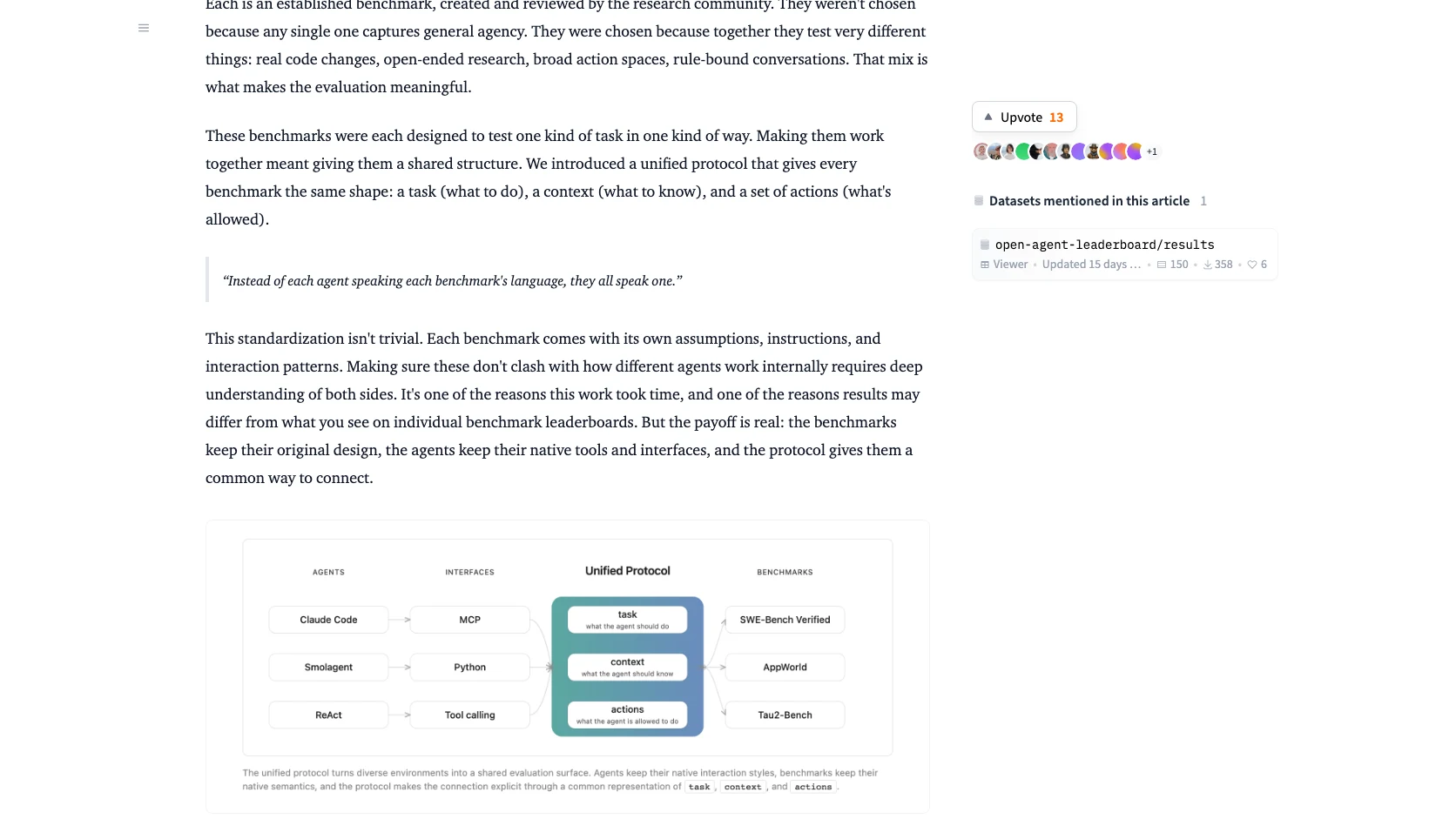
Que cambia con este leaderboard
La nota oficial deja claro que el benchmark no busca otra tabla de "quien gano esta semana". Lo que introduce es una forma más realista de responder una pregunta operativa: que sistema vale la pena desplegar.
El set inicial combina seis benchmarks ya conocidos, entre ellos SWE-Bench Verified, BrowseComp+, AppWorld y variantes de tau2-Bench. Eso importa por dos razones:
- El agente tiene que moverse entre tareas distintas, no solo una demo de coding o una sola política conversacional.
- Los resultados salen con calidad y costo, no solo con score bruto.
Para un builder de Latinoamerica esto es más útil que otro ranking de laboratorio. Si un agente mejora unos puntos pero duplica costo por tarea o falla caro, esa diferencia pega directo en margen, latencia y confianza de producto.
Lo mejor no es el ranking, es el tipo de evidencia
La parte más valiosa del lanzamiento no es ver quien va arriba hoy. Es que el dataset publico ya expone columnas como average_agent_cost, average_action_count, average_invalid_action_percent y average_score. Eso empieza a acercar la conversacion a lo que realmente duele en producción:
- Cuanto trabajo innecesario hace el agente antes de resolver.
- Cuantas acciones invalidas o desperdiciadas produce.
- Cuanto te cuesta un fallo largo frente a uno que falla rapido.
Ese cambió de enfoque se nota también en el texto de IBM: el equipo dice que algunos agentes generalistas ya compiten con sistemas especializados y que, cuando fallan, el costo del fallo puede crecer mucho. Ese matiz es más útil que una tabla bonita porque te obliga a pensar en presupuesto, no solo en ego técnico.
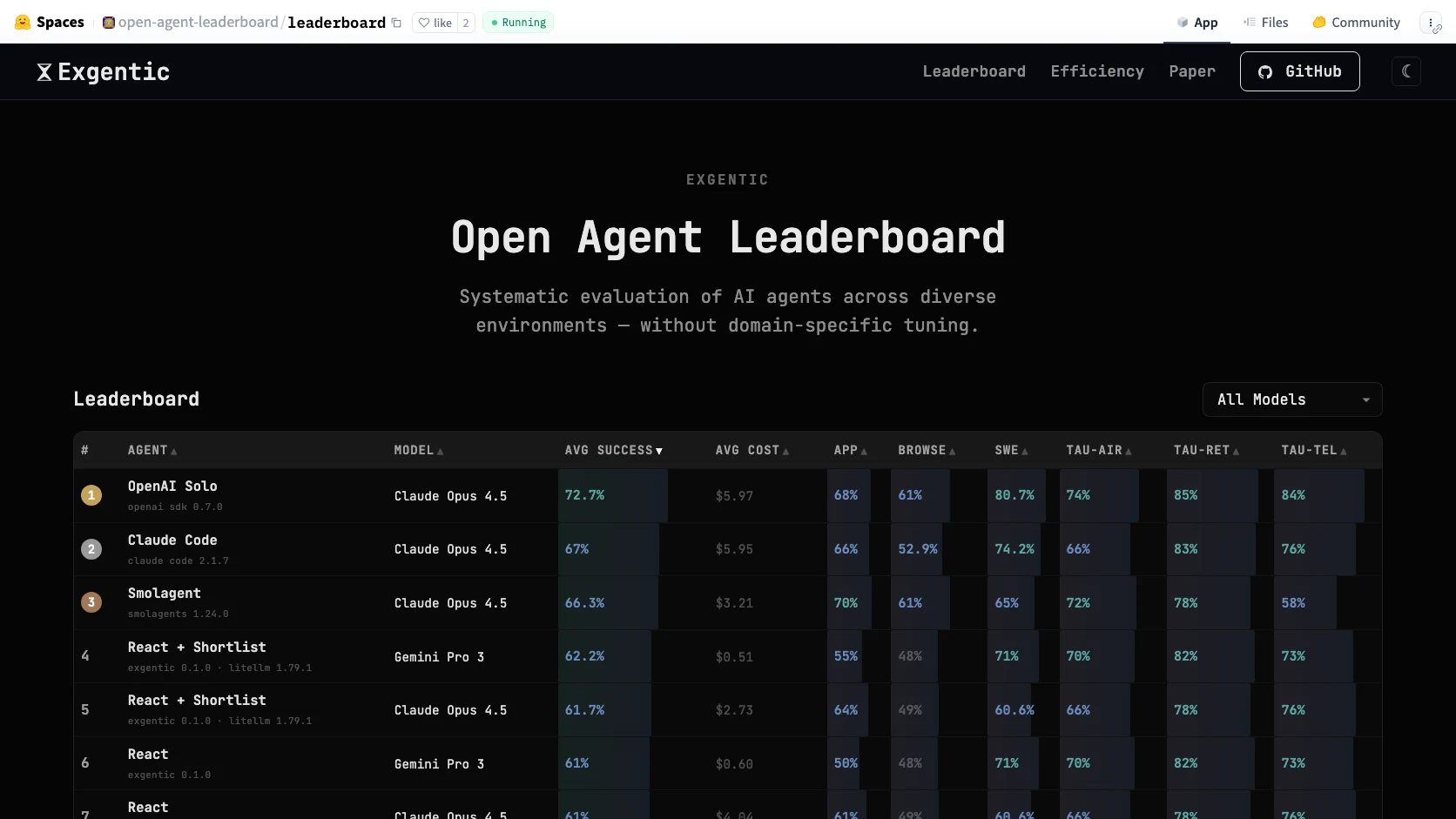
Como leerlo sin enganarte
Si vas a usar este leaderboard para decisiones reales, conviene leerlo con cuatro filtros.
El primero: no confundas generalidad con ajuste fino a tu tarea. Un agente generalista fuerte te da una buena base, pero no reemplaza pruebas sobre tu stack, tus permisos y tus herramientas.
El segundo: costo por tarea importa tanto como score. El dataset oficial ya lo deja visible. Si dos configuraciones estan cerca en calidad, normalmente gana la que falla más barato y usa menos pasos.
El tercero: mira la arquitectura, no solo el modelo. IBM insiste en que tool shortlisting y otros componentes agenticos ya cambian el resultado. Si cambias memoria, routing o set de tools, cambias el sistema que estas evaluando.
El cuarto: no lo uses para comprar humo enterprise. El leaderboard ayuda a detectar sistemas prometedores, pero no sustituye un eval privado con tus permisos, tus datos y tus criterios de handoff humano.
Donde si le veo valor práctico
Si hoy estas armando un agente de coding, soporte interno, research o automatizacion operativa, este lanzamiento te sirve en tres momentos concretos:
- Para descartar configuraciones que se ven bien en marketing pero queman demasiado costo.
- Para justificar por que el equipo necesita evaluar agente completo y no solo cambiar de modelo cada semana.
- Para documentar mejor tus propios evals internos: score, costo, pasos, errores y tasa de acciones invalidas.
En otras palabras, el Open Agent Leaderboard no te da la respuesta final, pero mejora mucho la pregunta. Y esa es justo la parte que faltaba en mucha cobertura de agentes.
Que haria un builder serio después de leer esto
- Toma un flujo real de tu producto, no una demo.
- Mide el sistema completo: modelo, tools, memoria, retries y costo.
- Usa el leaderboard como referencia externa, no como sustituto de tus pruebas.
- Guarda también tus fallos caros; ahí suele estar la optimizacion más rentable.
Si todavía te falta una base para instrumentar agentes con control, vale la pena complementar esta noticia con el curso gratis Instala Tu Propio Agente de IA y luego comparar contra nuestra guia sobre evals para agentes. La mezcla correcta no es benchmark o arquitectura. Es benchmark más arquitectura más criterio operativo.
La lectura final es simple: el benchmark útil para agentes ya no es "que modelo saco más puntos", sino "que sistema da mejor resultado por costo y con menos trabajo desperdiciado". Ese cambió de marco le conviene mucho más a quien va a desplegar que a quien solo quiere presumir ranking.