Mistral Search Toolkit convierte retrieval en producto: por que eso importa para RAG y agentes
Mistral lanzó Search Toolkit en public preview el 28 de mayo de 2026 con ingestion, retrieval y evaluación en el mismo framework. La novedad no es solo técnica: cambia como equipos pequenos pueden depurar RAG sin pegar herramientas sueltas.
Por qué importa
Esta nota se enfoca en la decisión práctica para builders: qué cambia, qué riesgo agrega y cómo aplicarlo sin romper operación.
La mitad de los problemas de muchos agentes con RAG no empieza en el modelo. Empieza en una pregunta mucho más incomoda: tu retrieval realmente encuentra lo correcto o solo parece que si? Mistral intenta responder esa brecha con Search Toolkit, anunciado el 28 de mayo de 2026 como framework abierto para ingestion, retrieval y evaluación en una sola pieza.
Eso importa porque demasiados equipos siguen montando RAG con una cadena fragil de scripts, vector store, prompts y dashboards separados. Cuando algo falla, nadie sabe si el problema es chunking, embeddings, reranking o generacion. El lanzamiento de Mistral va directo a ese dolor.

La noticia en terminos simples
Search Toolkit junta tres capas que normalmente viven separadas:
- Ingestion para extraer, partir y enriquecer documentos.
- Retrieval con opciones vectoriales y re-ranking.
- Evaluacion para medir si el buscador realmente devuelve contexto útil.
El blog de lanzamiento insiste en que los equipos pierden semanas armando plumbing antes de correr una consulta decente sobre sus propios datos. Si esa descripcion te suena exagerada, probablemente no has heredado todavía un stack RAG armado con cinco repos y tres supuestos incompatibles.
Lo interesante es que Mistral no lo vende solo como libreria de busqueda. Lo posiciona como base para agentes que necesitan contexto empresarial sin obligarte a separar ingestion, indexacion, evaluación y conectores como si fueran proyectos distintos.
Donde si puede mover la aguja
El mejor uso no es "hacer search porque si". El mejor uso es cuando tu agente necesita responder sobre corpus vivo y heterogeneo:
- wikis internas,
- tickets de soporte,
- repositorios de codigo,
- PDFs, hojas de calculo y correo,
- bases documentales donde el esquema cambia seguido.
En ese entorno, un framework que traiga ingestion, retrieval y evaluación en el mismo idioma reduce una clase muy cara de deuda técnica: la deuda de no saber que parte esta fallando.
Si el retriever va mal, Search Toolkit dice que puedes medir recall, precision, MRR y NDCG por separado. Esa es la parte valiosa. Por fin puedes dejar de culpar al prompt cuando el contexto recuperado ya venia roto.
Lo que más me convence del lanzamiento
No es que tenga "más features". Es que reconoce una verdad poco sexy: retrieval bueno necesita evaluación propia.
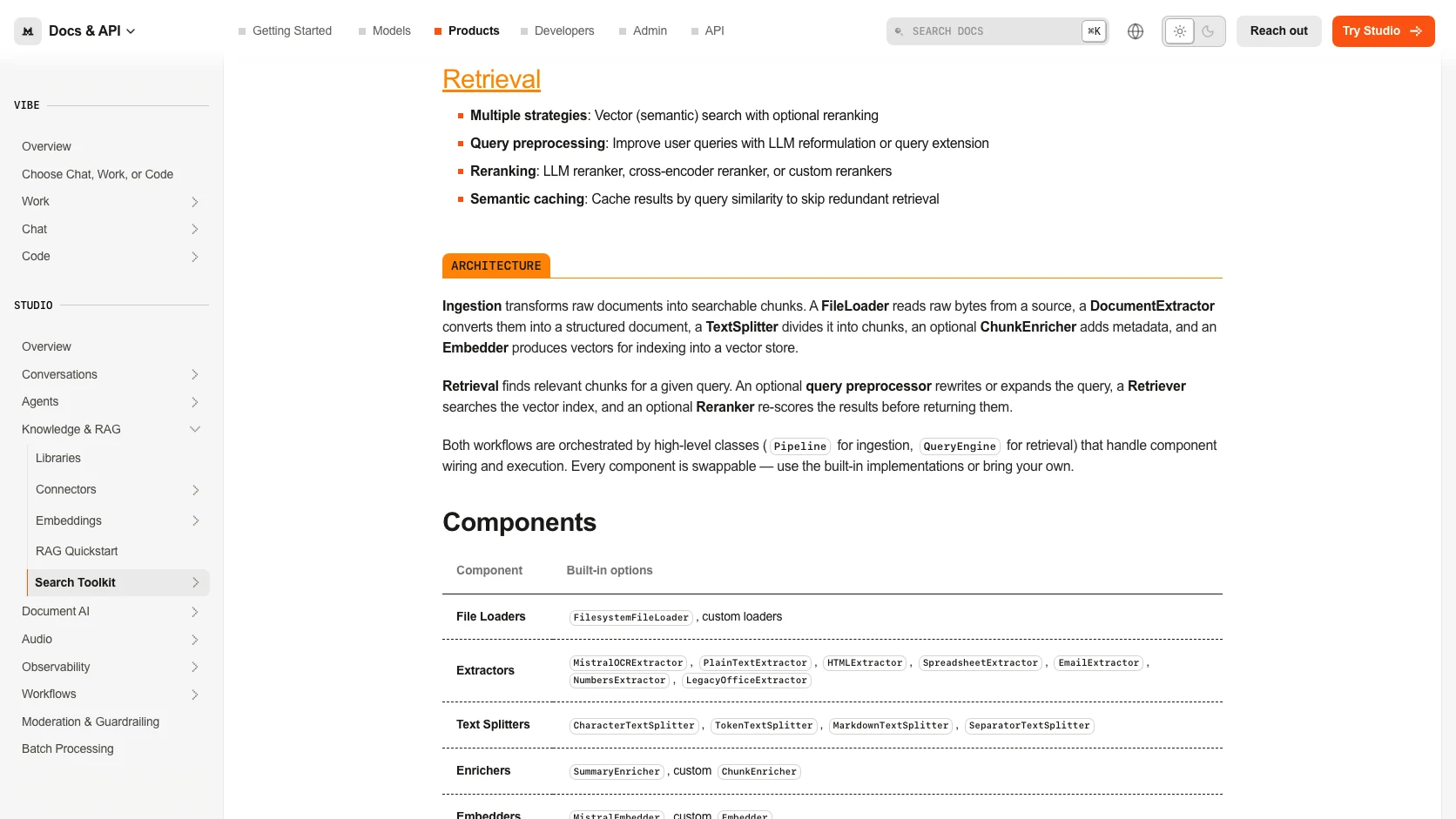
La doc oficial ya muestra componentes intercambiables para loaders, extractors, splitters, embedders, retrievers, rerankers y query rewriting. Eso no solo ayuda a customizar; ayuda a experimentar sin desmontar todo cada vez que cambias una pieza.
Para un equipo pequeno, eso es práctico por dos razones:
- Puedes aislar más rapido si el problema esta en indexing, en query expansion o en reranking.
- Puedes mejorar retrieval sin reescribir cada conector alrededor.
Los limites que conviene decir en voz alta
Search Toolkit no elimina el trabajo dificil. Solo te da un marco mejor para hacerlo.
Todavia vas a tener que decidir:
- como chunkear documentos raros,
- que metadatos importan para ranking,
- que corpus merecen index separado,
- como evaluas queries reales de tus usuarios,
- y cuando retrieval debe ceder ante busqueda en vivo o consulta directa a una fuente.
Ademas, la propia documentacion deja claro que el toolkit pide Python 3.12+ y apuesta por un stack técnico bastante explicito. Para equipos que viven en Node o en pipelines muy mezclados, la integración sigue siendo trabajo real, no magia.
Mi lectura práctica para builders
Si construyes agentes sobre documentos, soporte, compliance, operaciones o bases de conocimiento, este lanzamiento es valioso no porque "Mistral entró a RAG", sino porque empuja retrieval hacia una disciplina medible.
Eso cambia como deberias priorizar:
- Primero verifica que el retriever devuelve contexto correcto.
- Luego optimiza prompt, modelo y orchestration.
- Solo después te obsesiones con respuestas finales.
Este orden parece básico, pero en la práctica muchos equipos hacen lo contrario y terminan maquillando con prompt engineering un problema de retrieval que nunca midieron bien.
Que haria esta semana si me interesara adoptarlo
- Tomaria 20 consultas reales de usuarios o del equipo.
- Mediria resultados actuales del retriever.
- Probaria Search Toolkit con el mismo corpus y los mismos casos.
- Compararia calidad de retrieval antes de tocar el prompt final.
- Recien entonces evaluaria si vale migrar pipeline completo o solo una parte.
Si hoy tu base de agentes todavía esta verde, conviene combinar este enfoque con el curso gratis Instala Tu Propio Agente de IA y con nuestra guia sobre function calling y herramientas. La razon es simple: un agente útil no necesita solo buen retrieval; necesita retrieval medible y herramientas con contratos claros.
La noticia, entonces, no es "otro framework open source". La noticia es que Mistral puso ingestion, retrieval y evaluación en la misma conversacion, y eso acerca bastante más a los equipos pequeños a un RAG que se pueda mejorar con evidencia en vez de intuicion.