Microsoft Foundry empuja un trust stack para agentes: evals abiertas, controles portables y DLP dentro del loop
Microsoft presentó el 2 de junio de 2026 un paquete de capacidades para gobernar agentes en cualquier framework: ASSERT, Agent Control Specification, Rubric, simulacion de usuarios, replay de trazas y DLP en tiempo real. La clave no es otro dashboard: es mover seguridad y evaluación al flujo normal de construccion.
Por qué importa
Esta nota se enfoca en la decisión práctica para builders: qué cambia, qué riesgo agrega y cómo aplicarlo sin romper operación.
La mayoria de los anuncios sobre agentes siguen orbitando el mismo lugar: más tools, más memoria, más modelos, más velocidad. Microsoft intento mover la conversacion a otro punto en Build 2026, y vale la pena prestarle atencion.
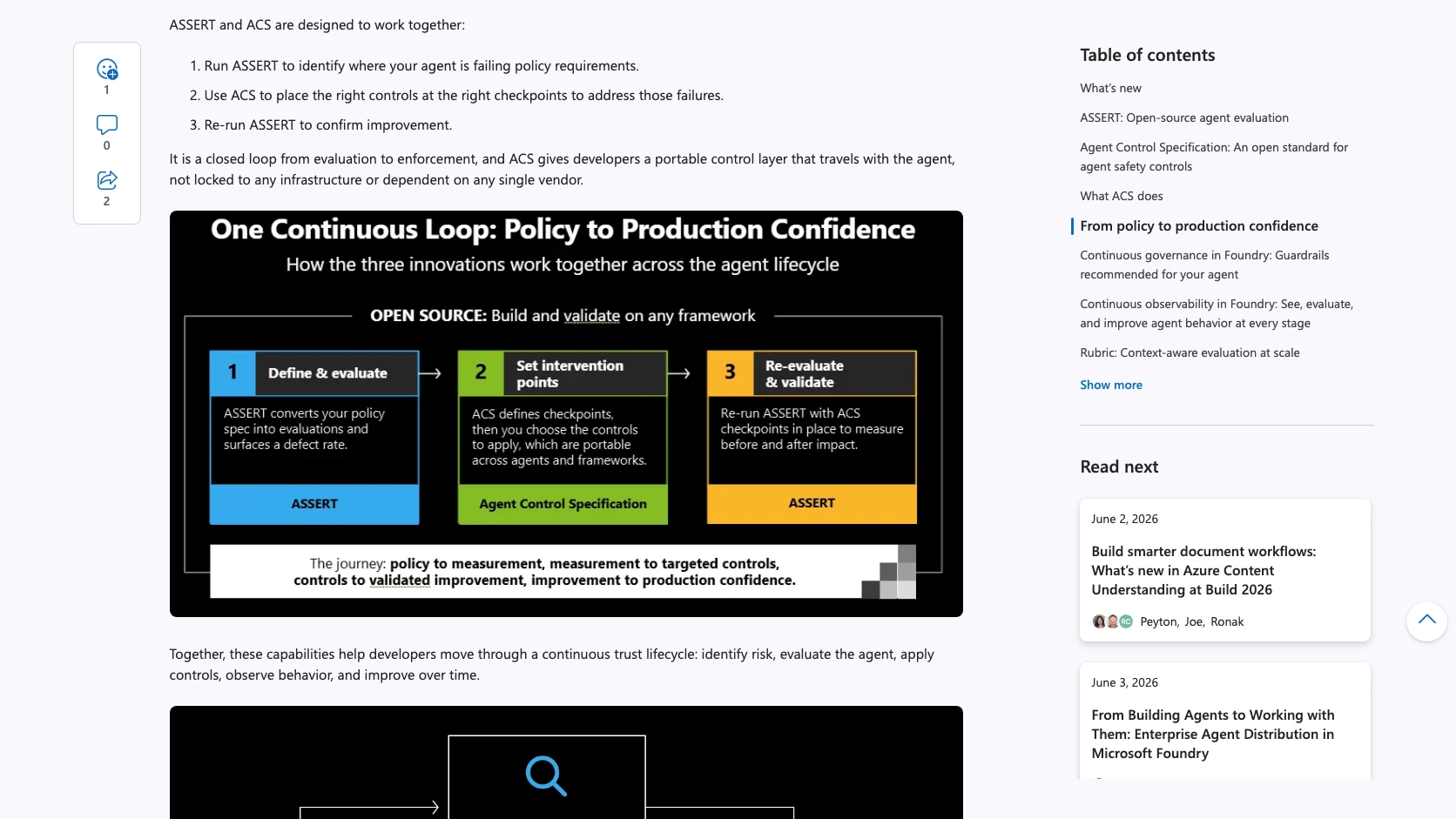
En su nota del 2 de junio de 2026, Microsoft Foundry junta varias piezas bajo una idea bastante clara: si un agente va a tocar datos, herramientas y decisiones reales, no basta con medirlo al final ni con ponerle un prompt más largo. Necesitas un trust stack donde evaluación, controles y proteccion de datos entren al flujo normal de construccion.
Eso aterriza en varios componentes:
- ASSERT para evaluar politicas y fallas;
- ACS o Agent Control Specification para poner controles portables;
- Rubric para generar criterios de calidad según contexto;
- simulacion de usuarios, replay de trazas y muestreo inteligente;
- y DLP en tiempo real dentro de la experiencia de desarrollo.
La mejor idea del anuncio: separar evaluar de controlar
Microsoft hace una distincion que muchos equipos siguen mezclando.
Una cosa es detectar que el agente esta fallando. Otra cosa es decidir donde y como intervenir. ASSERT y ACS estan pensados precisamente para esa separacion: primero encuentras el problema; después defines checkpoints y controles para corregirlo; luego vuelves a evaluar.
Ese orden es mejor que la rutina común de "viole una policy, reescribo prompt, pruebo dos veces y espero". Si tu seguridad depende solo de instrucciones, tarde o temprano tu agente encontrara un borde raro, una tool mal envuelta o un flujo multi-turn donde la policy se vuelve difusa.
La propuesta de ACS importa por otra razon: Microsoft lo vende como una capa portable. Si eso cuaja, el control del agente deja de quedar atrapado en un vendor, framework o runtime especifico.
Rubric y simulacion resuelven un problema real
Otra parte útil del anuncio es Rubric. Segun Microsoft, este evaluador genera criterios de calidad a partir del propio contexto del agente, y no de una lista estatica de checks.
Eso tiene mucho sentido. Un agente de soporte, uno de procurement y uno de incident response no fallan igual. Pedirles el mismo benchmark generico produce una seguridad falsa. Rubric intenta empujar hacia una evaluación más pegada al uso real.
Junto con eso llegan:
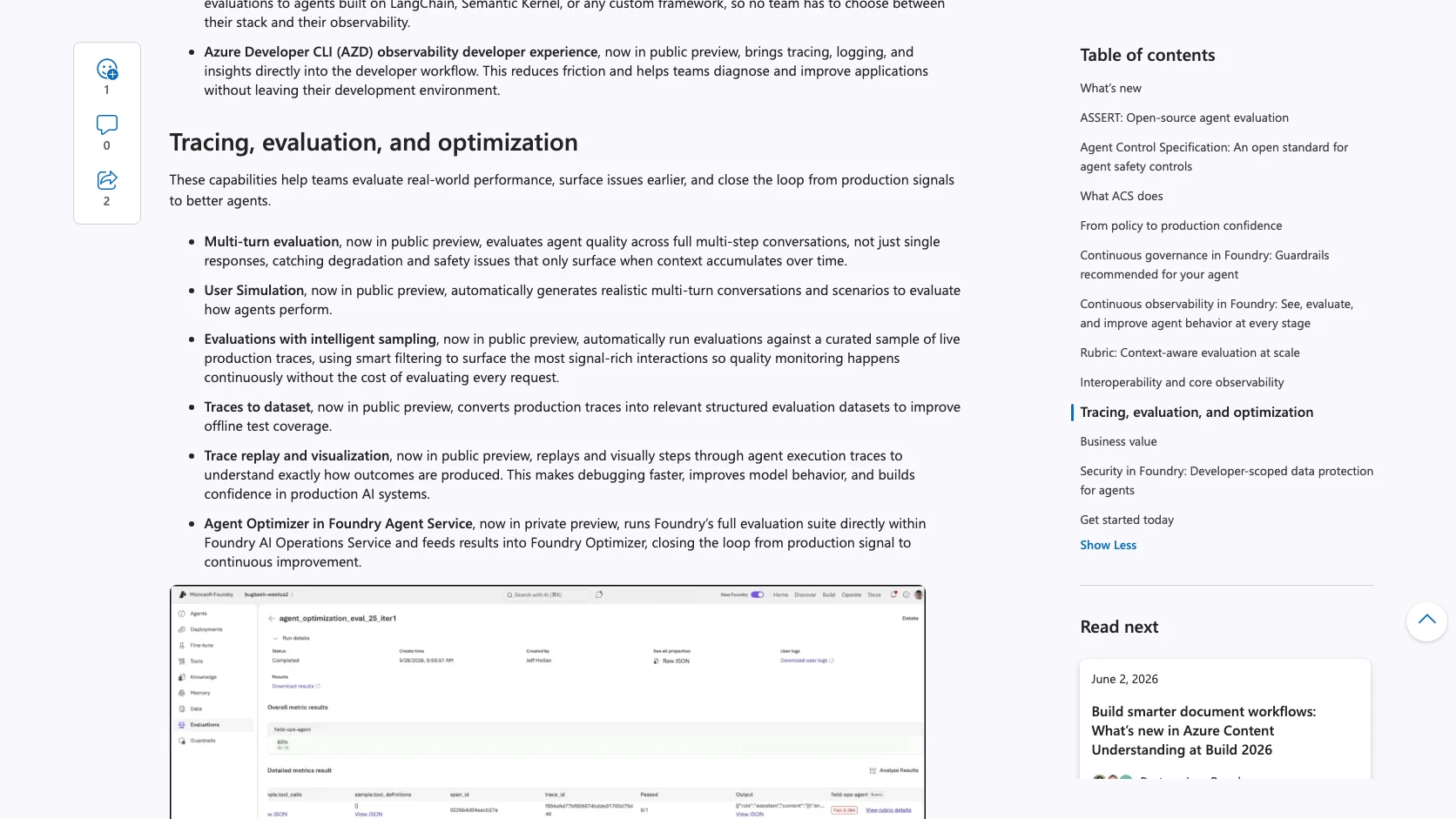
- multi-turn evaluation;
- User Simulation;
- intelligent sampling sobre trazas reales;
- y traces to dataset para convertir producción en material de evaluación.
La lectura práctica es potente: Microsoft quiere cerrar el loop entre "esto fallo en producción" y "aquí tienes un dataset, una traza y un criterio reproducible para arreglarlo". Eso es bastante más útil que otro leaderboard.
El anuncio también mete seguridad dentro del inner loop
La seccion que más me interesa no es la de evals, sino la de Developer-scoped data protection. Foundry mete Purview DLP dentro del desarrollo del agente para detectar y bloquear datos sensibles en prompts, respuestas e interacciones con tools.
Eso cambia una costumbre mala que ya se estaba normalizando: construir primero y pedirle a seguridad que "revise después". Si el agente ya toca PII, datos internos o rutas de negocio sensibles, revisar al final es demasiado tarde. El riesgo ya entró al flujo.
Que la proteccion aparezca en la misma experiencia del developer no resuelve todo, pero si cambia el sitio donde se toman decisiones. Ese movimiento me parece correcto.
Donde compite de verdad Microsoft
No creo que esta nota compita por "más features". Compite por algo más aburrido y más valioso: confiabilidad operativa.
Hoy muchos equipos pueden montar un agente que funcione en demo. Lo dificil es:
- saber cuando falla de forma sistematica;
- entender por que fallo;
- aplicar controles sin rehacer toda la arquitectura;
- y demostrar que el arreglo mejoro algo real.
Si lo miras así, esta noticia conversa directo con la nota reciente sobre Microsoft Foundry Agent Optimizer. Optimizer intenta mejorar el agente. Este trust stack intenta que esa mejora no sea una caja negra sin gobierno.
Los limites también importan
Tampoco compraria el paquete completo sin matices.
Primero, más evaluación no garantiza mejor criterio si defines mal tus escenarios. Segundo, un control portable sigue siendo tan bueno como los checkpoints que eliges. Tercero, meter DLP y observabilidad en el loop puede subir friccion si tu equipo no distingue entre proteccion necesaria y burocracia decorativa.
Y hay una trampa común: pensar que porque ahora tienes trazas, replay y simulacion, ya puedes delegar más autonomia. No necesariamente. Todo eso sirve para medir y restringir mejor, no para saltarte el trabajo de decidir que permisos merece el agente.
Que haria un builder serio después de leer esto
Si tu equipo ya tiene agentes en staging o producción, yo saldria con un checklist corto:
- elegiria dos o tres fallas que hoy se repiten;
- verificaria si ya tienes trazas suficientes para reproducirlas;
- definiria que controles deberian vivir fuera del prompt;
- y revisaria donde estas exponiendo datos sensibles sin una capa clara de enforcement.
Si todavía estas en la fase de "a ver si esto sirve", igual conviene leer la senal desde ahora. Porque el error más caro no suele ser escoger el modelo equivocado. Suele ser dejar que el agente entre a producción sin una manera sería de evaluarlo, limitarlo y explicar sus fallas.
La noticia de fondo no es que Microsoft tenga otro set de features para Foundry. La noticia es que esta empujando una idea correcta: la confianza en agentes no se agrega al final; se diseña dentro del loop de construccion.