Microsoft Foundry lanza Managed Compute: cuando el cuello de botella deja de ser el modelo y pasa a ser la plataforma
Microsoft anuncio el 3 de junio de 2026 Managed Compute para Foundry. La lectura útil para builders no es solo 'más GPUs': es una capa para servir modelos abiertos y pesos propios con el mismo endpoint, identidad y observabilidad que ya usan para frontier models.
Por qué importa
Esta nota se enfoca en la decisión práctica para builders: qué cambia, qué riesgo agrega y cómo aplicarlo sin romper operación.
El anuncio de Managed Compute en Microsoft Foundry del 3 de junio de 2026 vale más por lo que intenta eliminar que por lo que agrega. Microsoft no esta vendiendo otro dashboard para GPUs. Esta intentando quitar del medio la parte más lenta del trabajo con modelos abiertos en producción: elegir VMs, montar runtimes, parchar contenedores, cablear identidad, y luego sostener todo eso como si fuera producto.
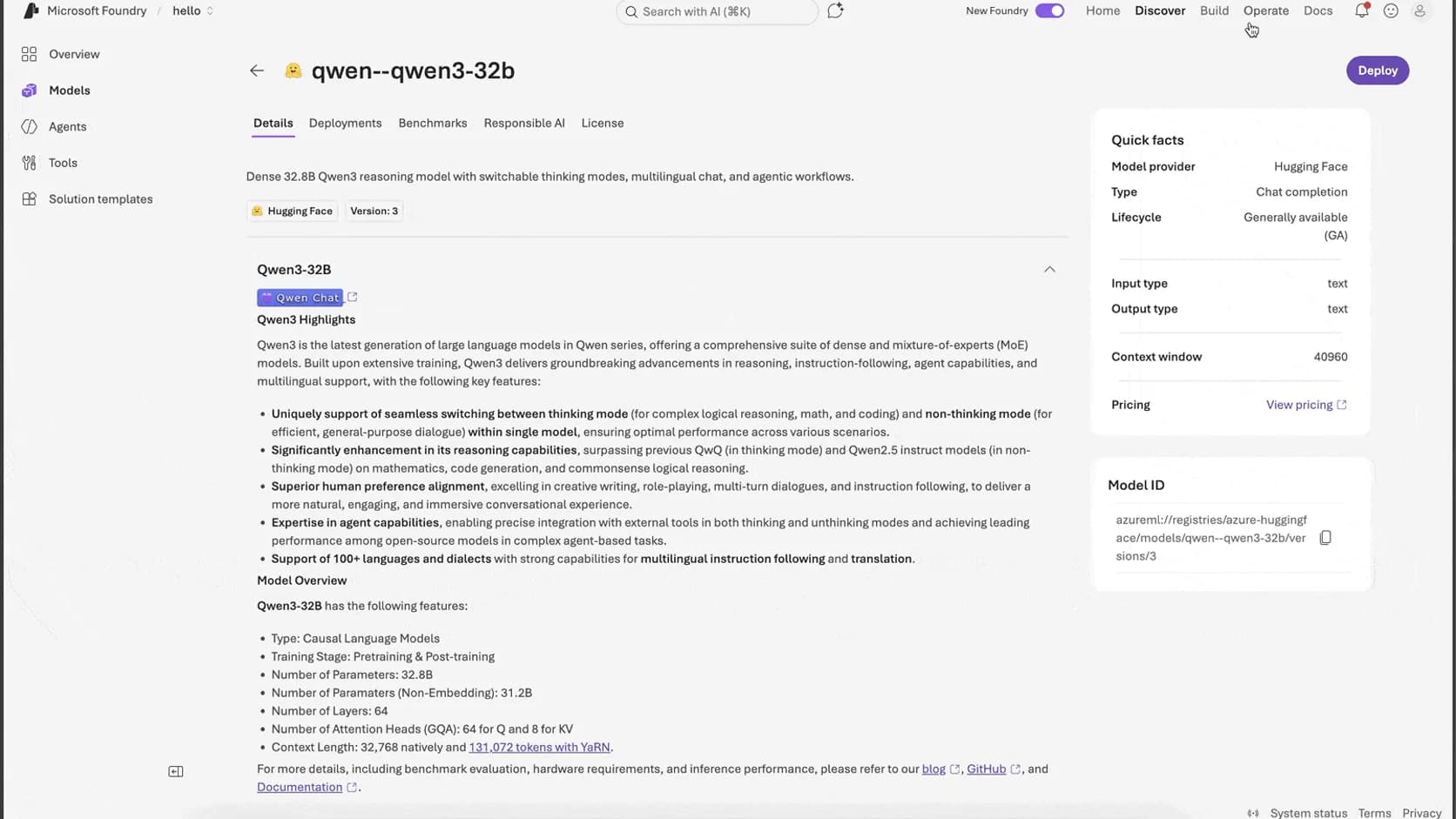
La promesa oficial es clara: usar modelos open-source o pesos propios detras del mismo endpoint, los mismos SDKs y la misma capa de gobierno que ya viven en Foundry para despliegues frontier. Si eso se cumple, cambia bastante la ecuacion para equipos que querian usar modelos abiertos pero no querian convertirse en operadores de infraestructura GPU a tiempo completo.
La mejor idea del anuncio: el modelo pasa a ser la unidad de despliegue
Microsoft lo dice casi textual: con Managed Compute, la unidad de despliegue es el modelo, no la maquina.
Eso importa porque el dolor real de servir modelos abiertos no suele empezar en el prompt. Empieza aquí:
- que familia de GPU necesitas;
- cuantas GPUs por replica;
- si la longitud de contexto rompe memoria;
- si la cuantizacion aguanta;
- y si el runtime que hoy funciona seguira parchado dentro de dos semanas.
Managed Compute intenta colapsar esa capa en tres decisiones: modelo, deployment template y accelerator family. Segun el anuncio, Foundry se encarga de poner debajo la cantidad correcta de GPU y de empacar runtime, contexto, cuantizacion y ajuste de latencia versus throughput dentro de la plantilla.
Eso no significa magia. Significa que Microsoft quiere mover la optimizacion de "que VM compro" hacia "que contrato operativo quiero para este modelo".
Donde si le veo valor rapido
Hay tres casos donde esta noticia tiene dientes de verdad:
- Equipos que ya usan Foundry para frontier models y quieren sumar open-source sin abrir otro stack entero.
- Builders que necesitan residency, RBAC o identidades gestionadas y no quieren resolver eso fuera de Azure.
- Flows de agentes donde un modelo abierto sirve mejor por costo, control o personalizacion, pero el runtime aun necesita parecerse a una plataforma, no a un laboratorio.
Microsoft también deja algo importante por escrito: los despliegues de Managed Compute aparecen bajo el mismo URL y credenciales de Foundry, y usan Microsoft Entra ID, managed identities, Azure RBAC y Azure Monitor metrics como el resto del entorno. Esa continuidad vale más que muchas demos de benchmarks.
La parte que debes leer con cuidado: no reemplaza todo, ordena una zona concreta
La tentacion es leer esto como "ya no hace falta pensar en infraestructura". No es verdad.
Sigue tocando decidir:
- que modelo sirve mejor para tu tarea;
- que latencia soporta tu producto;
- cuando usar open-source frente a serverless por token;
- y cuanto riesgo introduces si metes pesos propios o LoRAs dentro del loop.
Lo que Microsoft si esta comprimiendo es el costo cognitivo de operar esa decision dentro de una misma plataforma.
El tradeoff práctico: flexibilidad con opinion de plataforma
Mi lectura es esta: Managed Compute no compite contra "correr un modelo". Compite contra la opción de armar tu propio stack sobre VMs o Kubernetes cuando en realidad lo que quieres es enviar trafico, medirlo y dormir.
La ventaja obvia:
- menos bricolaje de infraestructura;
- observabilidad y costos más cerca del producto;
- identidad y networking ya integrados;
- y una ruta más natural para conectar esos modelos con agentes en Foundry.
El costo menos obvio:
- aceptas una opinion de plataforma sobre runtimes y plantillas;
- dependes de lo que Foundry soporte hoy y no de cualquier experimento raro;
- y varias piezas claves siguen en preview o en roadmap, como Data Zone Managed Compute, MI300X y Bring Your Own Weights.
Por eso no la venderia como la solucion universal. La venderia como una opción sería para quien ya supero la etapa de demo y necesita gobernanza sin meterse a reconstruir medio Azure.
Que haria un builder antes de subirse
Si evaluras esto hoy, yo haria cuatro preguntas antes de mover nada:
- Tu problema real es costo o control? Si solo quieres probar rapido, serverless por token puede seguir ganando.
- Tu flujo necesita un modelo abierto dentro de agentes o evals? Si si, tenerlo bajo el mismo endpoint simplifica bastante.
- Tu equipo esta listo para operar preview? Porque el anuncio disponible hoy sigue siendo preview.
- Tu seguridad exige identidad y RBAC integrados? Si esa respuesta es si, aquí es donde Managed Compute empieza a justificar su existencia.
Esta historia conversa muy bien con nuestra cobertura sobre Microsoft Foundry Agent Optimizer, porque una cosa mejora el comportamiento del agente y la otra intenta ordenar la capa donde corre el modelo que lo alimenta. Y si todavía estas armando la base de tools, memoria y criterios de despliegue, el aterrizaje más sobrio sigue siendo Instala Tu Propio Agente de IA.
Mi lectura final
Managed Compute importa porque Microsoft esta diciendo algo que muchos vendors todavía no aterrizan del todo: para agentes y apps de IA, el problema no es solo acceder a más modelos. El problema es poner modelos distintos bajo una misma disciplina operativa.
Si tu equipo ya vive en Foundry y empieza a mezclar frontier, open-source y personalizacion, este anuncio es bastante más que infraestructura. Es un intento de que la complejidad deje de vivir en la selección de la maquina y vuelva a vivir donde deberia: en la arquitectura del producto y en el criterio del builder.