KernelEvolve: Meta usa un agente para optimizar kernels y abrir 60% más throughput en horas
Meta explico el 2 de abril de 2026 como KernelEvolve trata la optimizacion de kernels como un problema de busqueda y no de codegen de una sola pasada. Para builders, la señal es clara: algunos agentes ya compiten mejor cuando exploran que cuando solo escriben.
Por qué importa
Esta nota se enfoca en la decisión práctica para builders: qué cambia, qué riesgo agrega y cómo aplicarlo sin romper operación.
La mayoria de builders mira a los agentes como herramientas para escribir codigo de aplicacion, buscar documentos o automatizar flujos. KernelEvolve, publicado por Meta el 2 de abril de 2026, empuja la frontera hacia otro sitio: usar un agente para optimizar kernels de producción sobre hardware heterogeneo.
Suena muy lejos de un builder promedio, pero el patron de fondo si es transferible. Meta reporta que KernelEvolve mejoro el throughput de inferencia en 60% en horas de experimentacion, un trabajo que habria tomado semanas a especialistas humanos. La parte que de verdad importa no es el número; es como llegó a ese número.
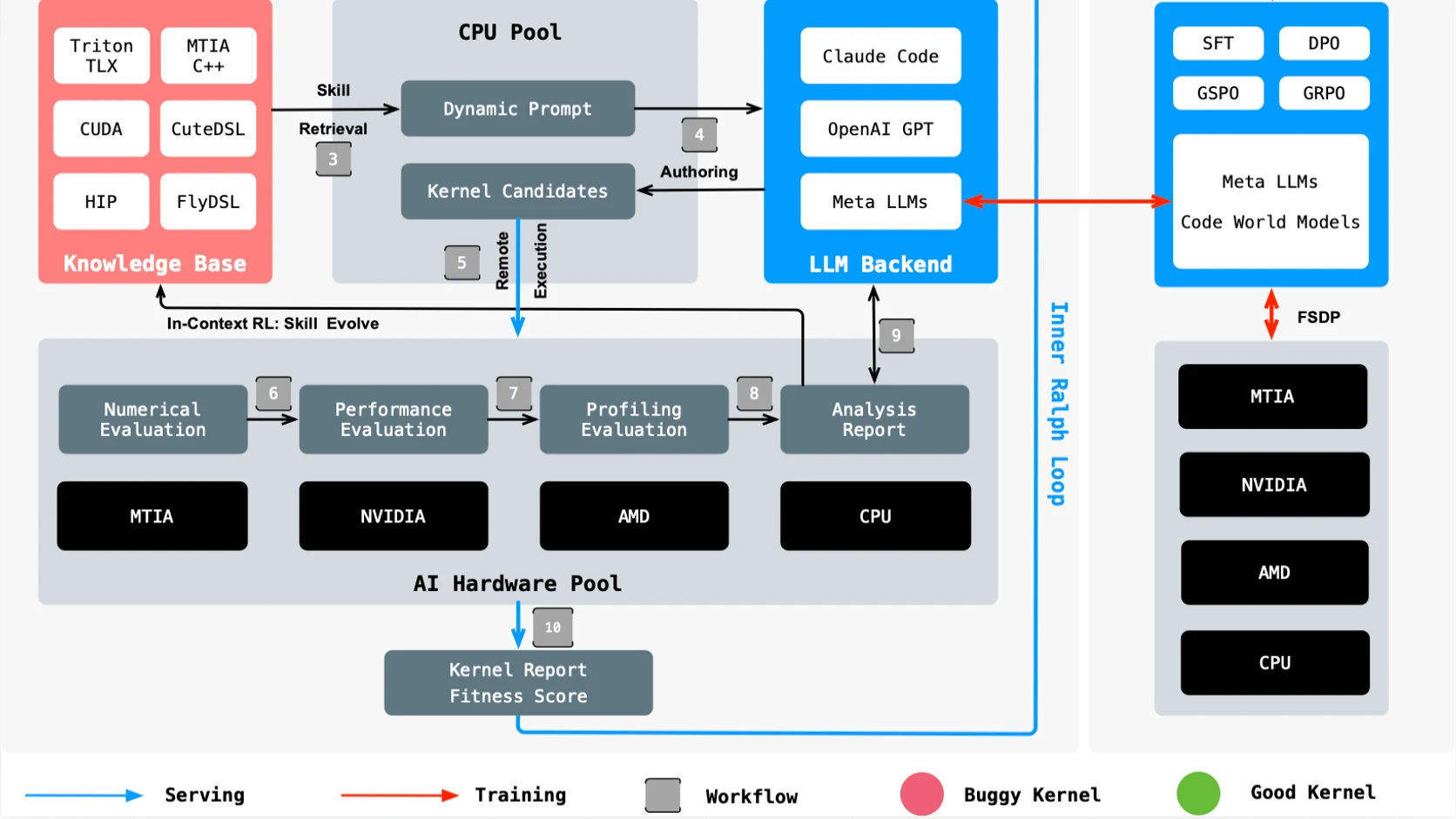
Aqui el agente no "adivina" el codigo; explora
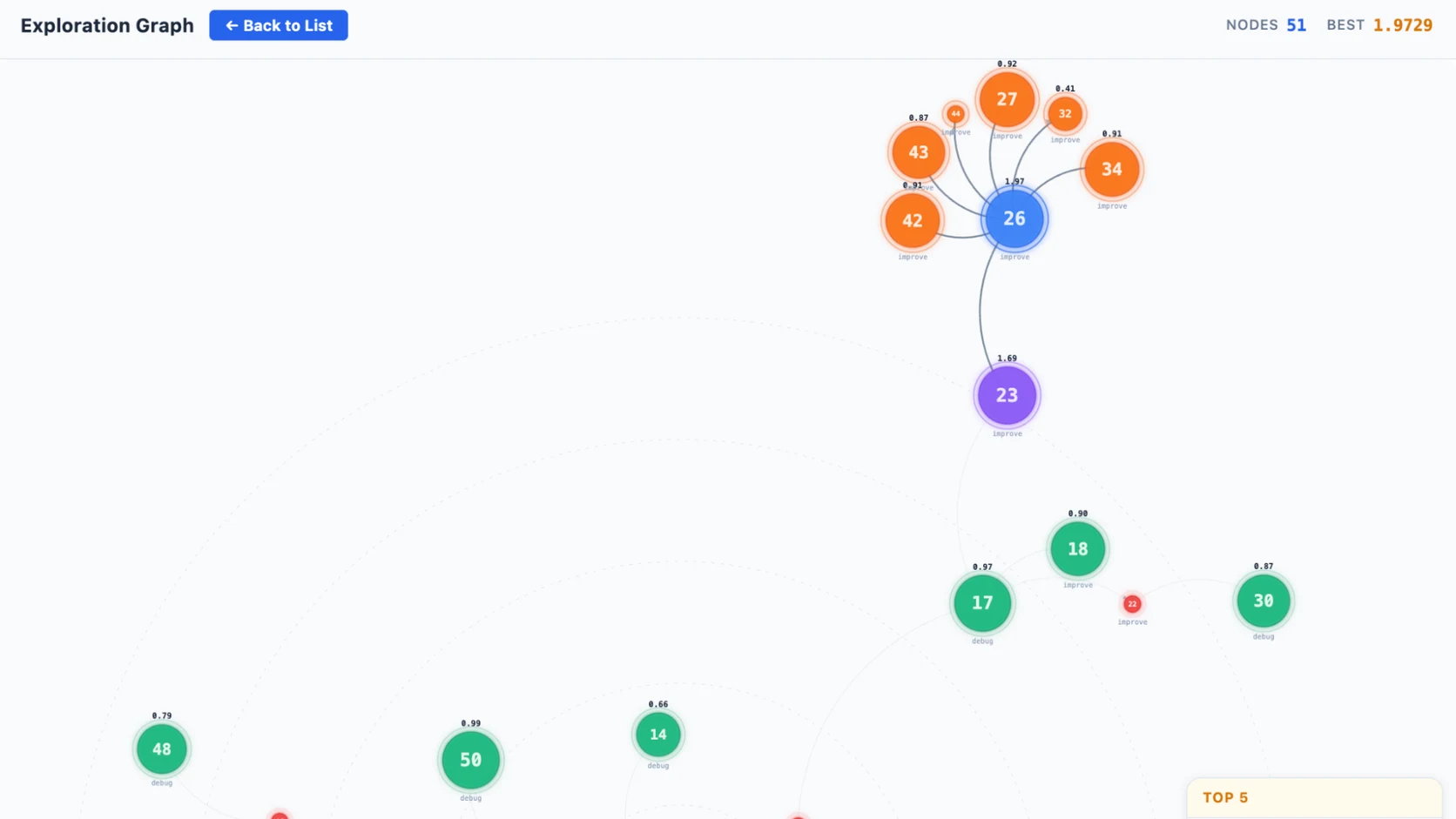
Meta dice algo que vale oro: KernelEvolve no trata la optimizacion como un problema de code generation one-shot. La trata como busqueda. Explora cientos de implementaciones alternativas y evalua cuales sobreviven mejor en hardware real.
Ese cambió de marco me parece más útil que cualquier benchmark aislado. Muchos agentes fallan cuando les pides una respuesta perfecta en la primera pasada. Mejoran bastante cuando el sistema les permite:
- generar variantes,
- probarlas,
- medirlas,
- descartar malas rutas,
- y seguir iterando con evidencia.
Eso no es solo teoria de infra. Es una pista muy concreta para cualquier builder que este montando agentes de deploy, debugging, tests o performance.
Por que esta noticia importa aunque nunca toques kernels
Kernel tuning parece un nicho hasta que recuerdas lo siguiente: todo el ecosistema de agentes esta chocando con problemas donde la mejor respuesta no sale de un solo intento, sino de una secuencia de propuestas y validaciones.
Meta lo aplica a kernels porque ahí duele más:
- miles de configuraciones entre hardware y operadores;
- hardware distinto entre NVIDIA, AMD, CPUs y MTIA;
- codigo que sirve billones de requests diarios;
- y cuellos de botella que un experto humano no puede retocar uno por uno a la velocidad que exige el stack.
Pero la misma logica vale para otros flujos:
- elegir una estrategia de retrieval y medirla;
- iterar sobre prompts de herramientas con evals reales;
- depurar fallos de CI comparando varias hipotesis;
- o refactorizar codigo donde hay varias rutas posibles y solo una pasa todas las pruebas.
La leccion estructural: search beats swagger
Todavia hay mucho contenido de agentes que vende una fantasia de "dile al modelo y el modelo resuelve". KernelEvolve empuja lo contrario. El agente fuerte no es necesariamente el que redacta mejor, sino el que:
- sabe generar alternativas,
- acepta feedback del entorno,
- conserva lo aprendido entre rondas,
- y opera dentro de un bucle con metricas claras.
Eso coincide con la forma madura de construir agentes. Primero diseñas el loop, luego eliges el modelo, luego decides donde vale la pena dejar explorar.
El tradeoff que no conviene esconder
Este tipo de agente no es barato ni trivial. Explorar cientos de variantes implica tiempo, evaluación y compute. El beneficio aparece cuando el espacio de busqueda es demasiado grande para una optimizacion manual razonable y cuando la ganancia final vale el costo.
Por eso no sacaria de aquí la conclusión de "todo debe volverse search". La conclusión correcta es más sobria:
- si tu tarea tiene una sola solucion obvia, probablemente no;
- si tu tarea necesita iteracion medible y el premio por acertar es alto, probablemente si.
En LatAm esto importa porque mucha gente quiere lanzar agentes antes de decidir que parte del problema merece exploracion y cual se resuelve mejor con reglas, tests y contratos.
Como usar esta noticia de forma práctica
Si te quedas con una sola idea, que sea esta: revisa tus flujos agenticos y pregunta donde hoy estas pidiendo demasiado de una respuesta one-shot.
Yo haria tres pruebas:
- identifica una tarea donde la primera salida rara vez es suficiente;
- convierte esa tarea en un loop de propuestas + validacion;
- mide si la segunda o tercera iteracion mejora más que simplemente cambiar de modelo.
Ese ejercicio suele revelar algo incomodo: a veces el cuello no es el modelo, sino el diseño del agente.
Esta nota se complementa bien con nuestra cobertura sobre como usar benchmarks para elegir modelo de agente, porque ambas empujan la misma conclusión: medir y validar importa más que enamorarse de una sola corrida. Y si todavía estas construyendo la base de tools, sesiones y despliegue, conviene arrancar por Instala Tu Propio Agente de IA antes de intentar loops de optimizacion más agresivos.
La lectura final es simple: KernelEvolve no solo muestra un caso extremo de Meta; muestra por que los agentes más utiles de 2026 se parecen cada vez menos a un autocomplete y cada vez más a un sistema de busqueda con memoria, validacion y criterio.