Meta encontró un cuello de botella real en coding agents: no faltaba modelo, faltaba mapa del codigo
Meta conto el 6 de abril de 2026 como uso más de 50 agentes para destilar conocimiento tacito en 59 archivos de contexto sobre 4,100 archivos reales. La leccion vale para cualquier equipo que quiera que un agente toque un repo privado sin inventar.

Por qué importa
Esta nota se enfoca en la decisión práctica para builders: qué cambia, qué riesgo agrega y cómo aplicarlo sin romper operación.
Hay una fantasia bastante extendida en coding agents: si cambias a un modelo mejor, el agente ya deberia entender tu repo. Meta acaba de publicar evidencia de que eso no basta. En una nota técnica del 6 de abril de 2026, la empresa explica que puso agentes sobre una pipeline interna enorme y el resultado inicial fue decepcionante: los modelos exploraban, adivinaban y producian cambios que compilaban, pero quedaban sutilmente mal.
El problema no era solo de razonamiento. Era de conocimiento tacito. La pipeline que describe Meta cruzaba cuatro repos, tres lenguajes y más de 4,100 archivos. Lo que rompe a un agente ahí no es un if complicado. Son las convenciones no escritas, los nombres intermedios, las dependencias cruzadas y las reglas heredadas que nadie documento bien.
Meta respondio con una idea más interesante que “poner más contexto en el prompt”: construyo un pre-compute engine de más de 50 tareas especializadas para leer el codigo, destilar reglas, criticarlas y convertirlas en una capa de navegacion reutilizable.
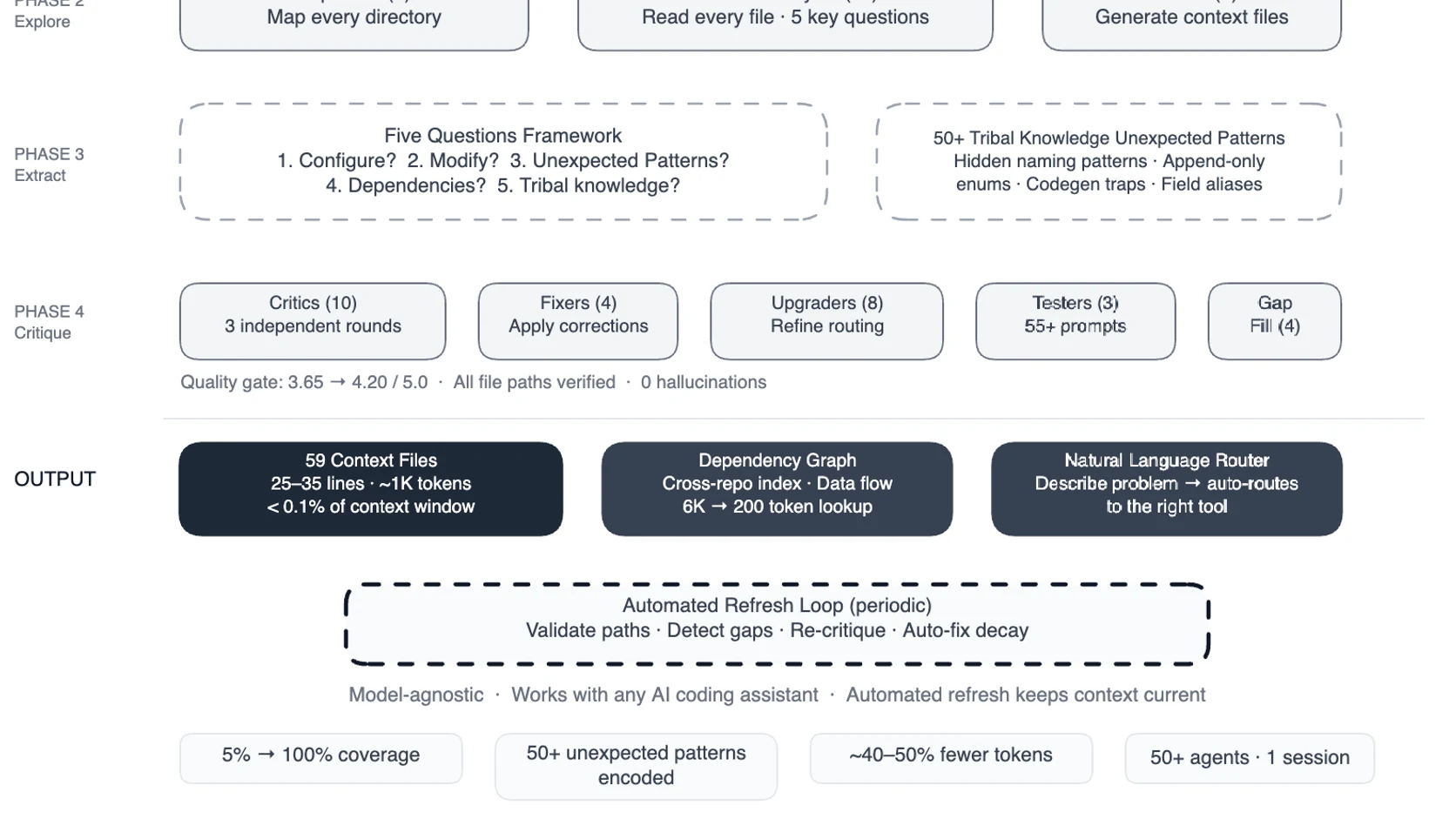
El teardown que más le sirve copiar a equipos pequenos
La empresa resume el sistema así:
- 59 archivos de contexto cortos,
- cobertura que paso de ~5% a 100% del mapa relevante,
- 50+ patrones no obvios documentados,
- y 40% menos tool calls y tokens por tarea en pruebas preliminares.
Lo importante no es el número exacto; es el diseño.
En vez de hacer una wiki enorme, Meta uso el principio "compass, not encyclopedia": archivos de 25 a 35 lineas, con comandos rapidos, archivos clave, patrones raros y referencias cruzadas. Es exactamente la direccion correcta para builders. Un agente no necesita una enciclopedia repetida del repo. Necesita una brujula accionable.
Tambien me parece acertado que no se quedaran en “explorer agents”. El flujo incluye:
- exploradores que mapean la base,
- analistas que responden cinco preguntas por modulo,
- escritores que sintetizan contexto,
- critics que revisan calidad,
- y jobs periodicos que refrescan archivos y corrigen decadencia.
Ese último paso es el que muchos equipos ignoran. Contexto viejo puede hacer más dano que no tener contexto. Meta lo dice sin rodeos: el sistema se autoactualiza cada pocas semanas, valida rutas y corrige huecos.
Las cinco preguntas que si puedes llevarte hoy
El marco de Meta para cada modulo es mejor de lo que suele verse en prompts genéricos:
- que configura o hace el modulo,
- como se modifica normalmente,
- que patrones no obvios suelen romper algo,
- de que otros modulos depende,
- y que conocimiento tacito estaba enterrado en comentarios o costumbre.
Eso es mucho más útil que pedirle al modelo “resume este folder”. Tambien explica por que el resultado fue portable entre modelos: la capa de conocimiento termina siendo model-agnostic.

Lo práctico para builders de LatAm
Si manejas un producto chico o mediano, no necesitas replicar la escala de Meta para llevarte la leccion. Necesitas aceptar tres cosas:
- tu repo privado tiene conocimiento que el modelo no vio nunca, aunque el benchmark del modelo sea brillante;
- el costo principal del agente no siempre es inferencia, muchas veces es exploracion torpe;
- la mejor mejora puede ser estructurar contexto, no cambiar de proveedor.
Meta dice que tareas que antes tomaban cerca de dos días de investigacion y consulta interna ahora bajan a alrededor de 30 minutos. No asumiria ese mismo ratio fuera de Meta, pero la direccion es creible: menos busqueda ciega, menos pasos redundantes, menos cambios casi-correctos.
Mi checklist mínimo para aplicar esto en un equipo real sería:
- detectar en que partes del repo fallan más tus agentes,
- crear 5 a 10 archivos de contexto por dominio, no por folder completo,
- obligar a cada archivo a incluir “lo que rompe” y “lo que no se debe borrar”,
- revisar esos archivos con otro agente o un humano antes de darlos por buenos,
- y refrescarlos cada vez que cambia la arquitectura.
Si todavía estas montando la base para tools, memoria y handoffs, el orden correcto es arrancar por Instala Tu Propio Agente de IA y luego comparar esta idea con nuestra arquitectura mínima de un agente en producción. Sin esa disciplina, un archivo de contexto se vuelve otro documento olvidado.
La noticia de Meta importa por una razon simple: rompe la narrativa de que el limite de los coding agents esta solo en el modelo. En repos privados, el verdadero cuello de botella suele ser otro: nadie le dio al agente un mapa confiable de donde esta parado.