LogRocket abre su MCP a todos: sesiones reales, metricas y tickets para que tu agente deje de debuggear a ciegas
LogRocket anuncio el 2 de junio de 2026 que su MCP ya esta disponible para todos. La parte útil para builders no es otro conector: es meter reproducciones reales, issues y metricas dentro del loop de Claude, Codex o Cursor antes de tocar codigo.
Por qué importa
Esta nota se enfoca en la decisión práctica para builders: qué cambia, qué riesgo agrega y cómo aplicarlo sin romper operación.
La mayoria de agentes para programar todavía viven con un problema básico: leen logs, tests y codigo, pero no ven lo que el usuario realmente sufrió antes de que alguien abra un ticket o una reproduccion manual.
Por eso el movimiento de LogRocket del 2 de junio de 2026 merece atencion. Su MCP server ya esta disponible para todos y conecta a Claude Code, Codex, Cursor y otros clientes MCP con sesiones reales, issues, metricas y consultas sobre Ask Galileo.
La noticia no es "otro MCP más". La noticia es que el agente puede entrar al loop con evidencia de producto en vez de inventarse la reproduccion desde cero.
Que cambia en la práctica
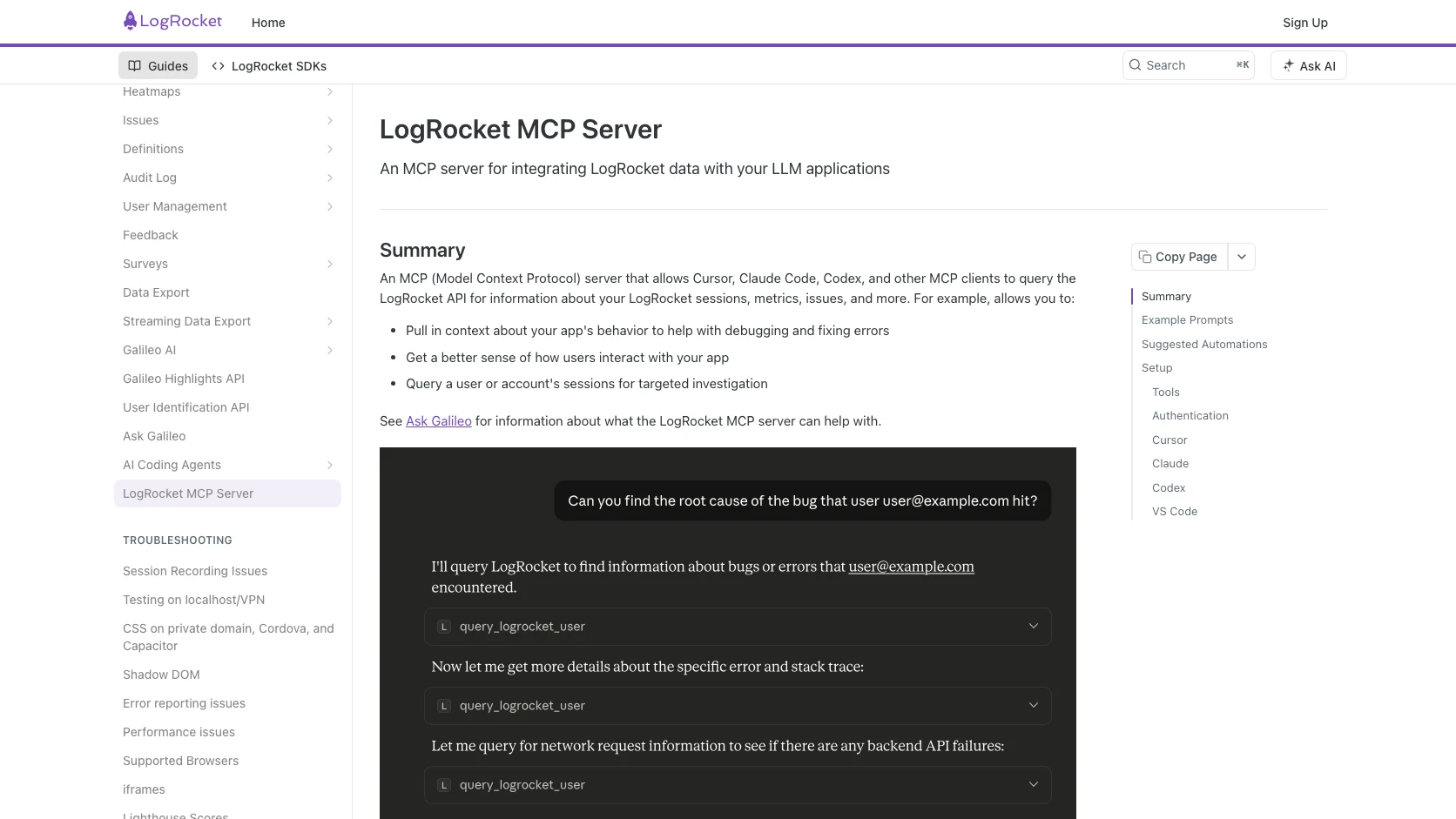
La documentacion oficial baja bastante el humo. Por defecto, el servidor expone tres herramientas:
list_organizationslist_projectsuse_logrocket
Y si quieres más detalle, puedes habilitar toolsets como:
sessionspara encontrar y mirar sesiones;metricspara consultar analytics;ask-galileopara consultas en lenguaje natural sobre issues y comportamiento.
Eso permite hacer algo que muchos equipos todavía resuelven mal: pasar de un reporte vago como "checkout se quedó cargando en mobile" a una investigacion guiada por sesiones reales, no por intuicion.
Donde si veo valor inmediato
Hay tres casos donde esto puede ahorrar tiempo real:
- bugs que no aparecen en local pero si en navegadores, cuentas o devices concretos;
- tickets de soporte que llegan sin pasos claros de reproduccion;
- caidas de conversion o retencion donde el problema no vive en el backend, sino en un flujo roto del frontend.
En la nota de lanzamiento, LogRocket empuja justo ese mensaje: tu agente deja de estar ciego frente a la experiencia del usuario. Y la doc lo hace más concreto con prompts tipo "mira las sesiones", "diagnostica la causa" o "usa metricas para entender el impacto".
El detalle técnico importante: alcance y autenticacion
La configuracion oficial soporta dos rutas que importan bastante:
- OAuth, recomendado cuando el cliente MCP puede autenticarse de forma interactiva;
- API key, útil cuando corres algo server-side o quieres limitarlo a un proyecto concreto.
Tambien puedes scopar el endpoint a una organización o a un proyecto especifico. Esa parte me parece más importante que el anuncio mismo, porque baja el riesgo de darle a un agente visibilidad innecesaria sobre toda tu cuenta.
Mi regla sería esta:
- arranca en un proyecto acotado;
- habilita solo los toolsets que tu flujo de debugging necesita;
- no conviertas la observabilidad en buffet libre para cualquier prompt.
Donde no conviene sobredimensionarlo
No lo venderia como solucion universal. El MCP de LogRocket ayuda mucho cuando el problema esta en comportamiento de usuario, regresiones de interfaz, formularios, embudos o performance percibida. Ayuda menos si el incidente vive solo en infraestructura interna, permisos de backend o datos que LogRocket no observa.
Tambien hay una nota explicita en la doc: las herramientas estan under active development. O sea, sirve para trabajar ya, pero el contrato todavía puede moverse. Eso importa si vas a montarle automatizaciones duras encima.
Por que esta historia tiene trafico cualificado
No hace falta inventar volumen para ver la intención:
logrocket mcpdebug session replay with ai agentclaude code logrocketcodex session replay bug fix
La persona que busca eso no esta explorando por curiosidad. Ya esta intentando cerrar el hueco entre soporte, producto y fix de ingenieria.
Si todavía no tienes bien amarrado el loop de verificacion en navegador, esta conversa directo con Chrome DevTools para agentes ya es estable. Y si sigues en la base de como estructurar un agente antes de meterle observabilidad, empieza por el curso gratis.
Mi lectura
Lo valioso de este lanzamiento no es que un agente "vea más dashboards". Lo valioso es que puede trabajar con evidencia de uso real antes de proponer un parche.
Eso no reemplaza criterio humano, pero si reduce una perdida de tiempo muy común: arreglar el bug equivocado porque nadie llevó la experiencia del usuario hasta el entorno donde el agente toma decisiones.