ITBench-AA pone a los agentes contra incidentes SRE reales y deja una mala noticia: nadie llega al 50%
Artificial Analysis e IBM lanzaron ITBench-AA el 27 de mayo de 2026 para medir agentes en incidentes Kubernetes reales. La lectura importante no es quien lidera hoy, sino que incluso los modelos frontier fallan demasiado cuando toca diagnosticar causa raiz con shell, logs y precision.

Por qué importa
Esta nota se enfoca en la decisión práctica para builders: qué cambia, qué riesgo agrega y cómo aplicarlo sin romper operación.
Los agentes se ven impresionantes mientras escriben codigo o responden preguntas. El problema empieza cuando tienen que diagnosticar una caida real, leer snapshots de Kubernetes, cruzar logs, traces, manifests y encima devolver la causa raiz mínima sin inventar ruido. Ahí entra ITBench-AA, publicado el 27 de mayo de 2026 por Artificial Analysis e IBM: un benchmark de tareas SRE agenticas donde la noticia más importante no es quien gana, sino que ningun modelo frontier supera el 50%.
Eso por si solo ya lo vuelve relevante. En un ecosistema lleno de benchmarks saturados, ITBench-AA abre una pregunta más incomoda y más útil: que tan bueno es tu agente cuando el trabajo ya no es contestar bonito, sino diagnosticar bien bajo restricciones reales?
Que mide y por que pega distinto
El benchmark arranca con 59 tareas SRE, de las cuales 40 son publicas y 19 estan reservadas. Cada tarea entrega un snapshot de incidente con alertas, eventos, trazas, metricas, logs, topologia y manifests de Kubernetes. El agente debe identificar el conjunto mínimo de entidades raiz que causaron el incidente.
El detalle metodologico importa mucho:
- el harness se mantiene constante para comparar modelos de forma pareja,
- cada tarea usa shell access sobre un filesystem sandboxeado,
- hay tope de 100 turnos por tarea,
- el score exige full recall: si omites una causa real, el puntaje cae a cero para esa repeticion.
Eso vuelve el benchmark más cercano al dolor operacional real. En incident response no basta con “casi acertar”. Si acusas al servicio equivocado o mezclas sintomas con causa raiz, el costo operativo es real.
Lo que el leaderboard ya esta diciendo
La publicación oficial resume cuatro datos que valen más que cualquier titular de “modelo X gana”:
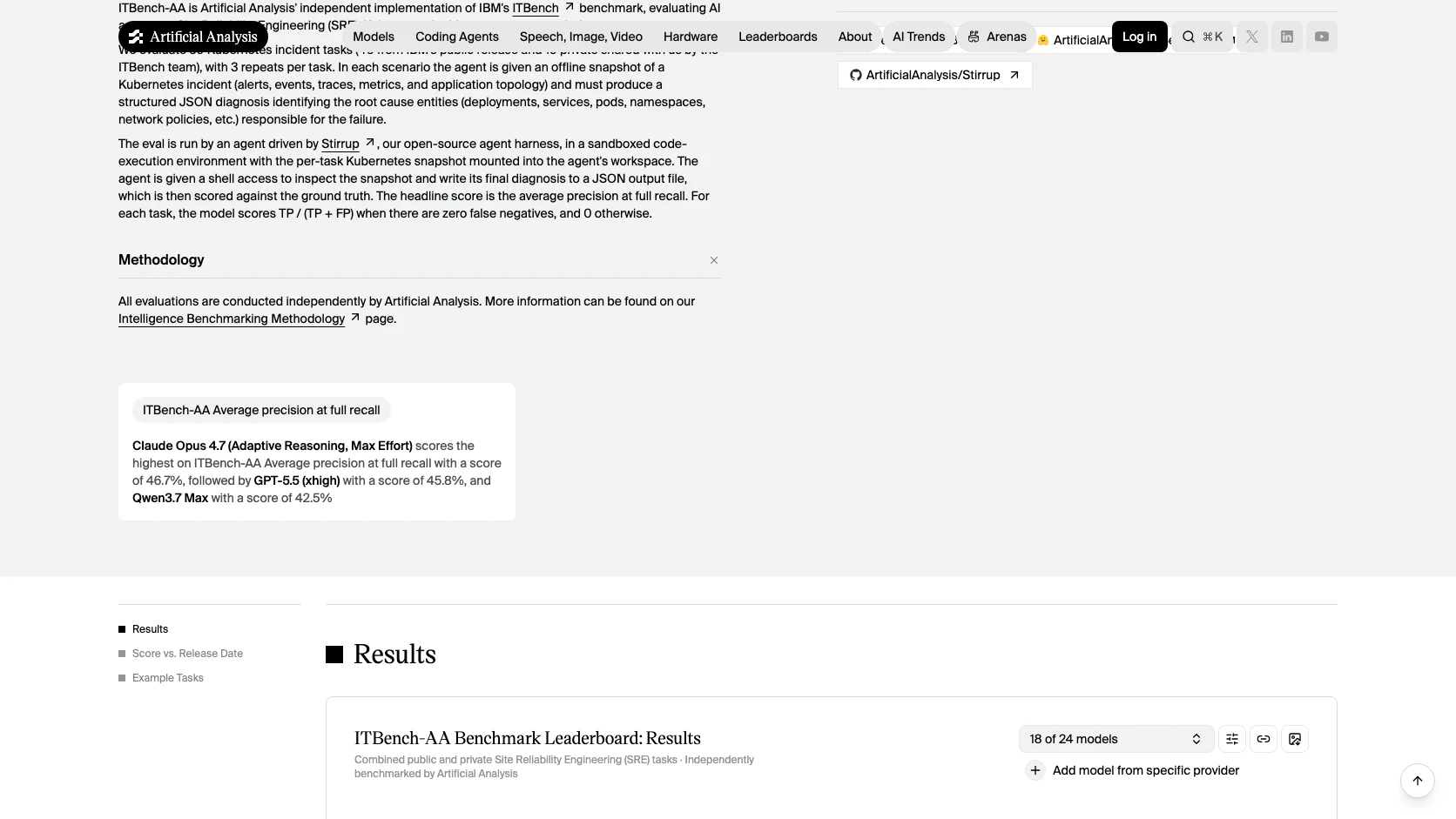
- Claude Opus 4.7 lidera con 47%, seguido por GPT-5.5 con 46% y Qwen3.7 Max con 42%.
- Todos quedan debajo de 50%, lo que vuelve a ITBench-AA una prueba poco saturada.
- Mas turnos no mejoran necesariamente el resultado.
- Los open weights ya pelean mejor en costo-rendimiento de lo que muchos equipos asumen.
Ese tercer punto me parece el más útil para builders. Según Artificial Analysis, Gemini 3.1 Pro Preview promedia 83 turnos y anota 30%, mientras GPT-5.5 promedia 31 turnos y queda en 46%. La leccion es dura: un agente que investiga de más puede verse trabajador, pero aun así diagnosticar peor.
Como deberias leer este benchmark
No como una tabla para elegir proveedor en abstracto, sino como una alerta metodologica.
Si tu equipo opera agentes para soporte técnico, plataformas internas, DevOps o troubleshooting, ITBench-AA te recuerda tres cosas:
- La precision estructurada importa más que el ruido elegante.
- La arquitectura del agente sigue contando, aunque el harness aquí este fijado para aislar el efecto del modelo.
- El costo por tarea no se puede separar de la calidad.
Artificial Analysis ya muestra que algunos open weights quedan mejor parados en costo que modelos frontier más caros. Eso no significa que debas migrar mañana. Significa algo más serio: si tu flujo depende de diagnósticos repetibles, tienes que medir tanto acierto como costo y longitud de trayectoria.
Donde un builder puede equivocarse
El error clasico después de leer un benchmark así es irse directo al podio. Yo haria lo contrario.
Primero preguntaria: mi agente también necesita full recall? En incidentes, casi siempre si. En otros flujos, quiza no.
Despues revisaria: que tan facil es para mi agente confundir mecanismos upstream con causa raiz? El benchmark penaliza justo ese comportamiento, y con razon.
Por último, mediria si mi stack premia agentes que “piensan mucho” aunque produzcan poca evidencia. ITBench-AA deja claro que una trayectoria larga no equivale a mejor diagnostico.
La acción práctica que deja esta noticia
Si trabajas con agentes operativos, este benchmark te sugiere una ruta concreta:
- arma un pequeño set interno de incidentes o tickets reales,
- exige salida estructurada, no solo narrativa,
- mide precision, costo y turnos,
- castiga explicitamente los falsos positivos que confunden sintomas con causa raiz.
Si todavía no tienes esa disciplina de evaluación, esta noticia conversa muy bien con nuestra guia sobre evals para agentes: por que una demo bonita no prueba nada. Y si quieres afinar la base operativa antes de soltar agentes sobre sistemas reales, el curso gratis Instala Tu Propio Agente de IA sigue siendo el mejor punto de arranque.
La lectura final: ITBench-AA no demuestra que los agentes ya resuelven SRE; demuestra exactamente lo contrario, y eso es valioso. Por fin hay una señal publica que obliga a dejar de confundir trayectorias largas con diagnostico confiable.