GitHub Copilot cloud agent ahora mezcla Auto y modelos baratos: como elegir sin disparar costo ni latencia
GitHub movió dos piezas entre el 14 y el 18 de mayo de 2026 para Copilot cloud agent: auto model selection y modelos más baratos para tareas simples. Juntas cambian la conversacion de builders que delegan trabajo real desde GitHub.
Por qué importa
Esta nota se enfoca en la decisión práctica para builders: qué cambia, qué riesgo agrega y cómo aplicarlo sin romper operación.
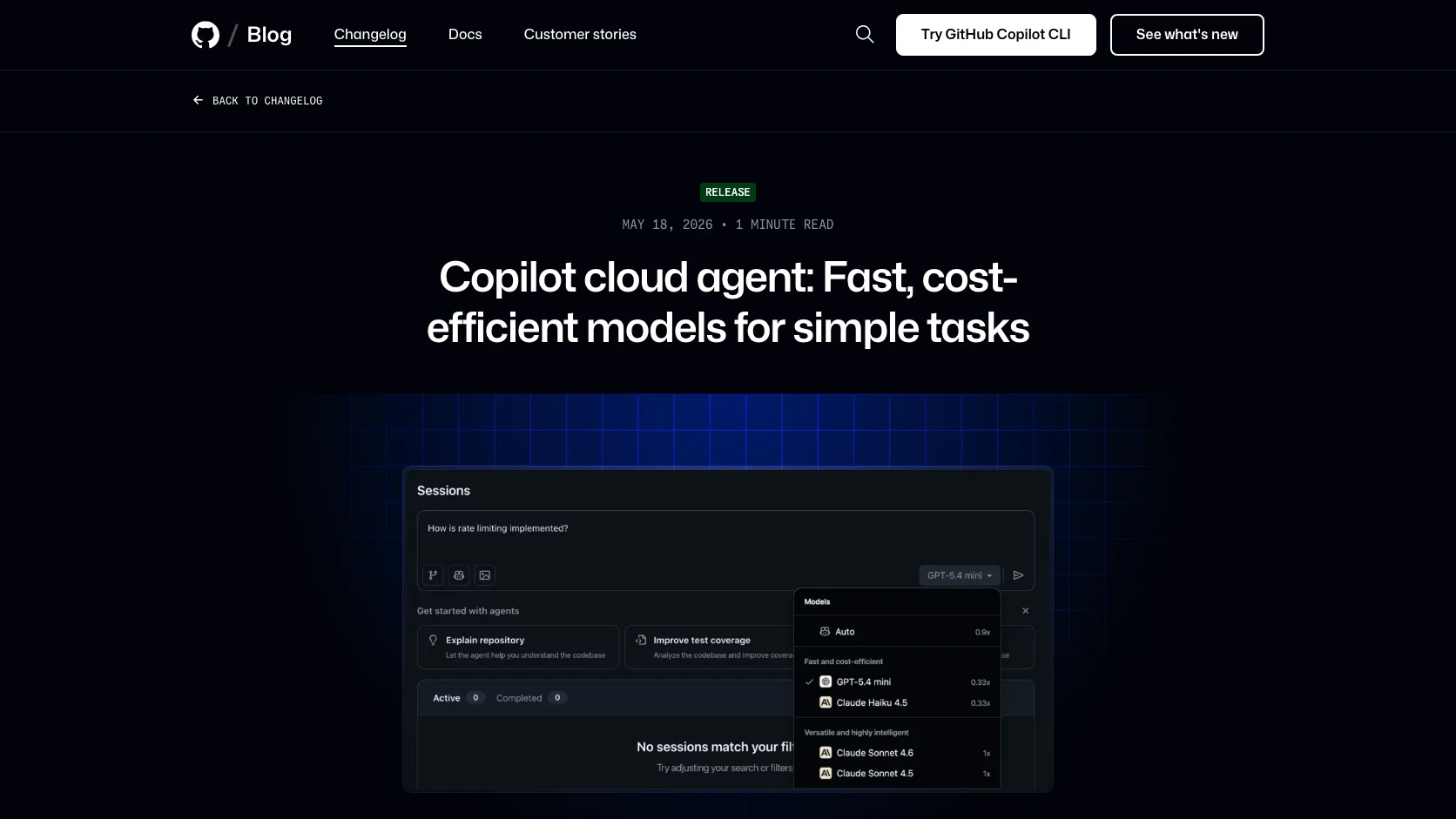
GitHub hizo dos cambios seguidos que juntos importan bastante más que por separado. El 14 de mayo de 2026 activó auto model selection para Copilot cloud agent y el 18 de mayo de 2026 agregó modelos más rapidos y baratos para tareas simples, incluyendo Claude Haiku 4.5 y GPT-5.4 mini con multiplicador de 0.33x.
Si delegas trabajo real desde GitHub, la historia no es “hay más modelos”. La historia es que GitHub ya esta empujando una capa de enrutamiento economico y operativo encima del agente.
Que cambia para el día a día
Hasta hace poco, elegir modelo en un agente cloud tendia a ser una decision estatica: ponias uno “bueno”, asumias el costo y listo. GitHub esta moviendo eso hacia algo más dinamico.
Segun el changelog y la documentacion oficial:
- si eliges Auto, Copilot selecciona el mejor modelo disponible según salud del sistema y performance del modelo;
- Auto también viene con 10% de descuento sobre el multiplicador normal y evita afectar tus weekly rate limits en ese flujo;
- y cuando quieres salirte de Auto, hoy tienes una lista concreta de opciones soportadas para cloud agent, incluyendo Claude Sonnet 4.5, Claude Opus 4.7, Claude Haiku 4.5, Gemini 3.1 Pro, Gemini 3.5 Flash, GPT-5.2-Codex y GPT-5.4 mini.
Eso ya no es solo “selector de modelo”. Es política de operación.
Mi lectura: GitHub quiere que pienses por tipo de tarea
La incorporacion de Haiku 4.5 y GPT-5.4 mini como opciones de menor costo deja una senal clara: GitHub espera que no todo trabajo del agente necesite el modelo más caro.
Eso tiene mucho sentido si separas tareas como:
- cambios pequenos de config;
- ajustes repetitivos de docs;
- correcciones sencillas en tests;
- o limpieza mecanica de codigo.
Para ese tipo de trabajo, un modelo más rapido y barato puede ser suficiente. Reservar un modelo más capaz para migraciones complejas, debugging raro o refactors largos deja de ser una intuicion y empieza a parecer una política razonable.
Ojo: Auto no reemplaza criterio
La tentacion es pensar: “si Auto decide, ya no me preocupo”. Error.
Auto reduce friccion, pero no responde preguntas que siguen siendo tuyas:
- Que tareas son realmente simples?
- Que tan caro te sale una respuesta mala aunque el modelo sea barato?
- Cuando conviene fijar un modelo por cumplimiento, reproducibilidad o debugging?
Si un agente toca permisos, despliegues, dependencias sensibles o cambios que después disparan CI caro, el costo del modelo puede ser menor que el costo del error.
Por eso yo separaria el uso así:
- Auto para exploracion, tareas rutinarias y colas de bajo riesgo.
- Modelo fijo barato cuando quieres controlar gasto en trabajo acotado.
- Modelo fijo fuerte cuando el impacto de un fallo supera por mucho el ahorro.
Donde esta la oportunidad editorial y de busqueda
Las consultas fuertes aquí son directas:
copilot cloud agent model selectioncopilot auto model selectiongpt-5.4 mini copilotclaude haiku copilot cloud agent
La demanda actual se infiere facil por la combinacion de changelogs, docs oficiales y el interes creciente por controlar costo de agentes sin romper productividad. No hace falta inventar volumen para ver la intención: quien busca esto ya esta decidiendo presupuesto, throughput o defaults para su equipo.
El detalle menos obvio: no siempre veras el picker
La documentacion de GitHub aclara algo que muchos anuncios esconden: la selección de modelo para cloud agent no aparece en todos los entrypoints. Hoy aplica en superficies concretas, como asignar un issue a Copilot en GitHub.com, mencionar @copilot en un comentario de PR o iniciar sesiones desde tabs y paneles compatibles. Donde no hay picker, Auto se usa por defecto.
Eso importa porque evita una falsa expectativa de control uniforme. Si tu equipo usa varias superficies, toca verificar donde de verdad puede forzar modelo y donde no.
Como lo probaria sin improvisar
Haria un experimento corto de tres carriles:
- tareas triviales con Auto;
- tareas repetibles de bajo riesgo con Haiku 4.5 o GPT-5.4 mini;
- tareas complejas con un modelo premium fijo.
Luego compararia:
- tiempo de entrega;
- tasa de correccion manual;
- fallas en CI o revisiones;
- y costo efectivo por cambió útil.
Si todavía estas afinando el contrato base del agente, primero te conviene revisar algo como GitHub Copilot SDK en GA o bajar a fundamento con el curso gratis, porque elegir modelo sin tener claro el loop de herramientas y permisos es optimizacion prematura.
La senal fuerte aquí es otra: GitHub esta convirtiendo el selector de modelo en una decision de operación, presupuesto y riesgo, no solo de preferencia personal. Para equipos que ya delegan trabajo real al agente, ese cambió pesa bastante más que cualquier release aislada de un modelo nuevo.