Gemini API File Search ya entiende imagenes, metadata y citas por pagina: por que eso si mueve el RAG de agentes
Google actualizo Gemini API File Search el 5 de mayo de 2026 con soporte multimodal, metadata personalizada y page-level citations. Para builders, la noticia es simple: menos pegamento para RAG verificable y menos excusas para devolver respuestas sin trazabilidad.
Por qué importa
Esta nota se enfoca en la decisión práctica para builders: qué cambia, qué riesgo agrega y cómo aplicarlo sin romper operación.
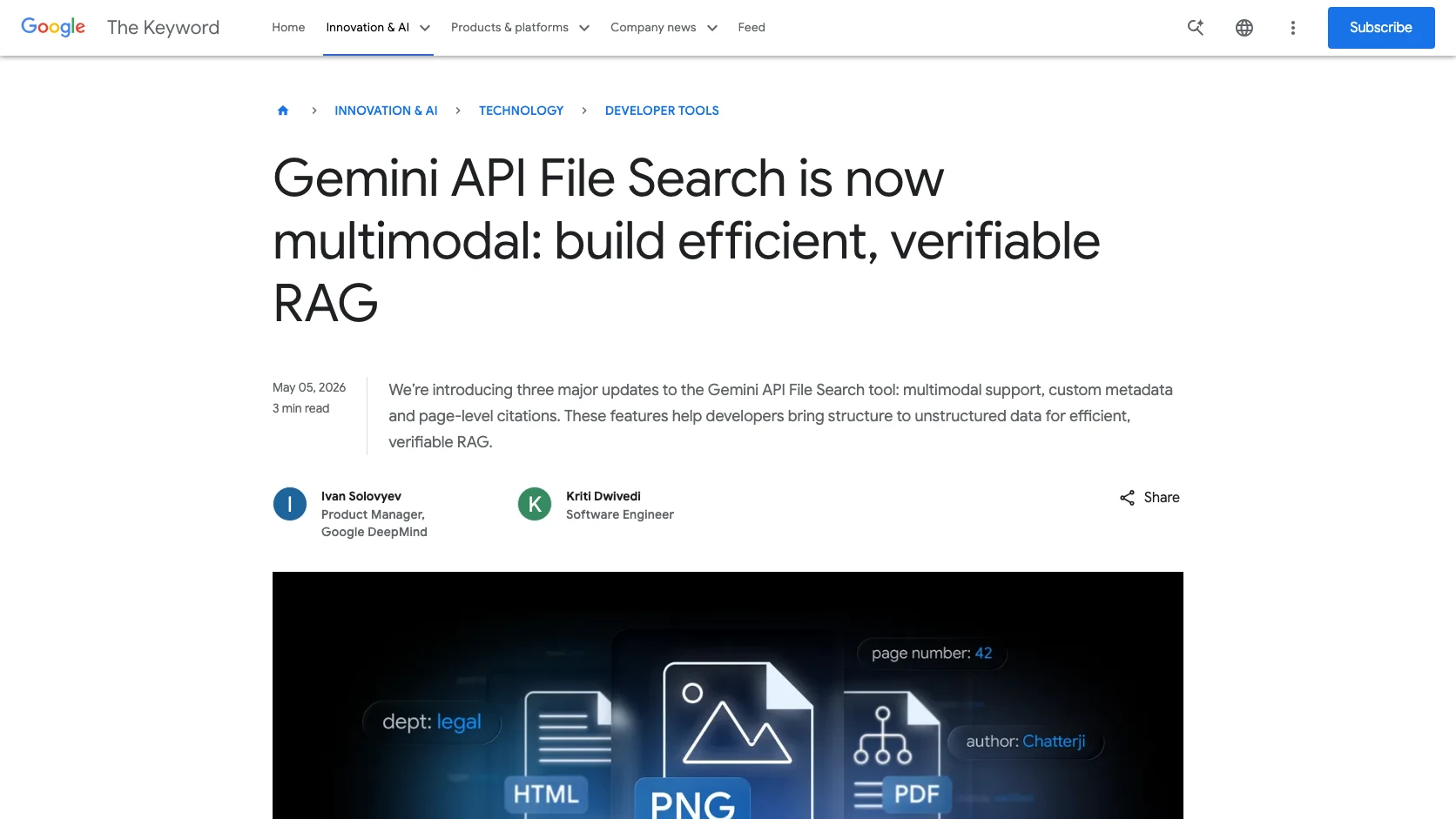
Hay muchas demos de RAG que responden bonito y muy pocas que resisten una pregunta incomoda: "muéstrame exactamente de donde salió eso". La actualización de Gemini API File Search del 5 de mayo de 2026 va justo contra ese problema.
Google añadió tres cambios al tool de File Search: soporte multimodal, custom metadata y page-level citations. Traducido al idioma de un builder: el retrieval puede mirar mejor archivos mezclados, filtrar menos a ciegas y devolver evidencia más útil cuando alguien necesita verificar una respuesta.
La mejora importante no es "multimodal"
La palabra vende, pero el impacto práctico no empieza ahí. Empieza en que Google esta reduciendo tres pedazos de pegamento que muchos equipos terminan implementando mal:
- pipelines separados para texto e imagen,
- filtros improvisados para acotar contexto,
- citas vagas que dicen "según el PDF" pero no ayudan a auditar nada.
Cuando Google dice que File Search ahora procesa texto e imagen usando Gemini Embedding 2, esta apuntando a un caso real: repositorios documentales donde el conocimiento no vive solo en texto corrido. Vive en diagramas, capturas, PDFs escaneados, tablas y reportes visuales.
Eso pega fuerte en agentes que trabajan con:
- manuales operativos,
- procesos internos,
- artefactos de producto,
- documentos tecnicos con anexos visuales,
- flujos regulatorios donde la fuente original importa.
Por que las citas por pagina importan más de lo que parece
Este es el cambió que yo pondria en el titular si buscara trafico cualificado.
Page-level citations no son un adorno para compliance. Son una mejora de producto para cualquier equipo cansado de respuestas que parecen correctas pero no se pueden revisar rapido. Si el agente puede decirte pagina exacta, no solo el archivo, el usuario tarda menos en:
- comprobar si la respuesta esta bien,
- detectar contexto omitido,
- decidir si puede usar esa salida en una tarea de negocio.
Esa diferencia entre "encontre la fuente" y "encontre la pagina" es la clase de detalle que separa un RAG bonito de un RAG útil.
Donde la metadata personalizada si te ahorra dinero
Muchos equipos solo piensan en metadata cuando el sistema ya esta lento o ruidoso. Google lo formaliza como feature de producto y eso es buena señal.
Poder adjuntar campos como department, status o cualquier etiqueta de negocio ayuda a recortar el espacio de búsqueda antes de que el modelo empiece a razonar sobre basura documental. Menos ruido suele significar tres cosas:
- menos contexto irrelevante,
- mejores respuestas,
- menos costo por consulta.
No es glamoroso, pero es exactamente el tipo de mejora que conviene en agentes internos de soporte, legal, ventas o operaciones.
Lo que esta noticia cambia para builders hispanos
Si construyes para pymes, agencias o equipos medianos, esta actualización baja el umbral para lanzar algo verificable sin inventarte media plataforma.
Antes, para acercarte a este nivel, normalmente acababas mezclando:
- vector store,
- pipeline OCR o visión aparte,
- capa manual de filtros,
- formato propio de citas.
Ahora Google empaqueta más de eso como primitive de plataforma. No resuelve toda la arquitectura, pero si recorta complejidad en una zona donde muchos MVP se rompen.
Errores de lectura que conviene evitar
Esta noticia no significa que cualquier base documental ya quedó resuelta.
Sigue habiendo preguntas serias que tu equipo debe responder:
- quien sube y limpia archivos,
- como versionas cambios,
- que documentos no deben indexarse,
- cuando una cita por pagina igual necesita revision humana,
- que parte del workflow merece cache y cual no.
Tambien hay un riesgo clasico: creer que "multimodal" equivale a comprensión perfecta. No. Entender mejor imagenes y texto mezclados no elimina la necesidad de evals con casos reales.
Que haria esta semana si ya tengo un agente con RAG
- Identificaria una coleccion documental donde hoy fallas por mezcla de texto e imagen.
- Probaria filtros de metadata que reflejen negocio real, no etiquetas decorativas.
- Mediria si las citas por pagina reducen tiempo de validacion humana.
- Compararia costo y calidad contra tu pipeline actual.
Si todavía no tienes ese marco de evaluación, esta nota conecta bien con evals para agentes: por que una demo bonita no prueba nada. Y si estas en fase de base técnica, Instala Tu Propio Agente de IA sigue siendo un buen punto de partida antes de montar retrieval serio.
La lectura final es simple: Google no solo agrego una feature; movió File Search más cerca de un RAG defendible en producción. Para builders, eso vale más que otra demo de chat con PDF.