Claude Code explica su bajon de calidad: el postmortem que todo builder de agentes deberia leer
Anthropic detallo el 23 de abril de 2026 tres cambios que degradaron Claude Code, el Agent SDK y Claude Cowork. La leccion práctica no es el bug en si, sino como evaluar latencia, memoria y prompts sin romper calidad.

Por qué importa
Esta nota se enfoca en la decisión práctica para builders: qué cambia, qué riesgo agrega y cómo aplicarlo sin romper operación.
No todas las noticias utiles sobre agentes son un launch brillante. A veces la señal más valiosa es un postmortem bien escrito. Eso fue justo lo que publico Anthropic el 23 de abril de 2026: una explicacion concreta de por que Claude Code, Claude Agent SDK y Claude Cowork se sintieron peores para parte de los usuarios durante marzo y abril.
La nota importa porque no habla de "sensaciones". Habla de tres cambios de producto que, combinados, redujeron calidad de forma real. Y el punto fuerte para builders es este: los agentes se rompen no solo por el modelo, sino por defaults, memoria de sesion y prompt layer.
Que se rompio exactamente
Anthropic dice que encontró tres causas separadas y que la API no estuvo afectada:
- El 4 de marzo bajaron el razonamiento por defecto de
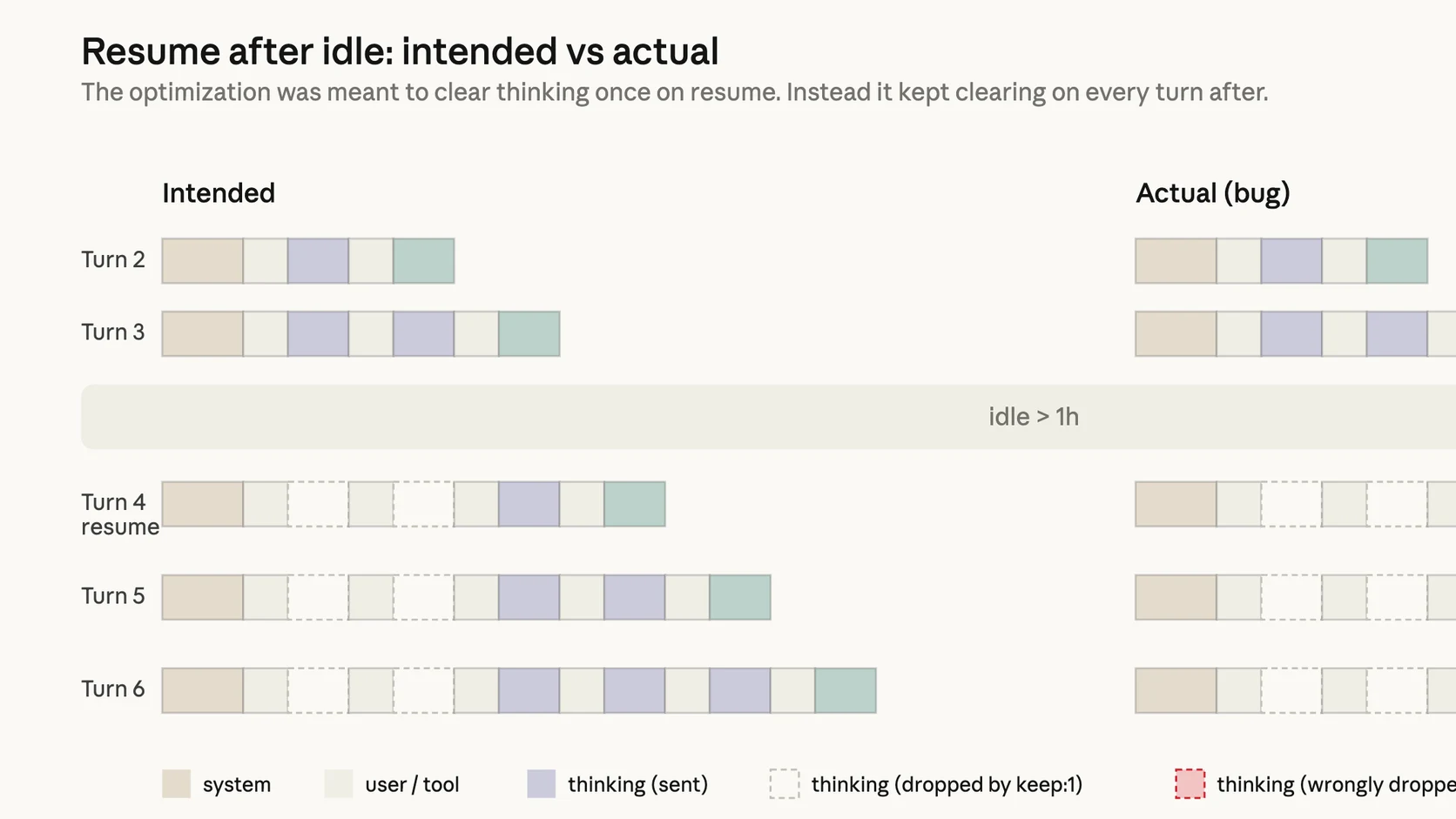
highamediumpara reducir latencia y evitar que la UI pareciera congelada. - El 26 de marzo introdujeron una optimizacion para limpiar razonamiento viejo en sesiones inactivas, pero un bug hizo que esa limpieza siguiera ocurriendo en cada turno posterior.
- El 16 de abril agregaron una instruccion al system prompt para volver más breve a Claude Code, y esa regla terminó golpeando la calidad de coding.
Anthropic revirtio o corrigio los tres problemas entre el 7 y el 20 de abril, y como parte del cierre reseteo los usage limits de los suscriptores.
La parte útil para un builder no es "Anthropic cometio errores". La parte útil es ver donde estaban esos errores: en la capa de orquestacion y experiencia, no en un benchmark abstracto del modelo.
Primer aprendizaje: latencia y calidad casi nunca se negocian gratis
El primer cambió es el más facil de malinterpretar. Anthropic no empeoro el producto "porque si". Intento resolver una friccion real: sesiones donde high effort tardaba tanto que parecia freeze. El problema es que la solucion elegida fue bajar la inteligencia por defecto.
Eso pega con algo que muchos equipos en LatAm siguen tratando como detalle cosmético: un agente no tiene solo un modelo; tiene un perfil de esfuerzo, latencia y costo. Cuando cambias el default para mejorar UX, puedes estar moviendo el sistema a otro punto de la curva de calidad.
Si tu agente hace soporte, debugging o research con tools, no basta medir "tiempo total". Necesitas medir:
- calidad de la respuesta final,
- tiempo al primer output útil,
- número de tool calls,
- y tasa de reintento o backtracking.
Sin esas cuatro señales, cualquier recorte de latencia puede esconder una caida de inteligencia.
Segundo aprendizaje: la memoria operativa del agente es parte del producto
El segundo problema me parece el más serio para builders. Anthropic explica que un bug hacia que, después de cierto tiempo ociosos, algunos hilos siguieran perdiendo bloques de razonamiento en turnos posteriores. El resultado visible fue un agente más repetitivo, olvidadizo y raro al elegir tools.
Eso encaja con la documentacion publica de prompt caching: el cache ayuda a bajar costo y latencia, pero los agentes dependen de como conservan y reinyectan contexto entre turnos. Si esa capa se rompe, el agente puede seguir "funcionando" mientras toma peores decisiones.
Muchos equipos solo monitorean errores fatales. Este caso muestra por que también hay que instrumentar degradaciones blandas:
- perdida de contexto después de idle,
- loops de herramientas sin progreso,
- respuestas cada vez más genericas,
- y drenaje anormal de usage o tokens por cache misses.
Tercer aprendizaje: tocar el system prompt de un coding agent es tocar el producto entero
La linea que Anthropic cita da miedo por lo familiar que suena: limitar a 25 palabras el texto entre tool calls y a 100 palabras la respuesta final salvo excepciones. Eso parece un ajuste razonable si solo persigues menos verbosidad. Pero según Anthropic, combinado con otros cambios, redujo calidad en coding y mostró una baja del 3% en una evaluación más amplia.
La conclusión es incomoda y útil: un system prompt corto no es igual a un system prompt inocente. En agentes de coding o de operaciones, la forma en que el modelo explica, decide, pide contexto y resume estado afecta directamente la calidad del trabajo.
Si manejas prompts de agente como copy o estilo editorial, vas tarde. Deben pasar por:
- evals por modelo;
- pruebas largas con sesiones viejas;
- ablations o diffs linea por linea;
- y rollout gradual.
Lo que Agente IA haria con esta noticia
Si hoy operas cualquier agente con tools, me quedaria con este checklist:
- No cambies defaults de esfuerzo sin medir calidad, no solo latencia.
- Trata cache y memoria como infraestructura critica del agente.
- Versiona y audita tu prompt layer como si fuera codigo.
- Guarda ejemplos reproducibles de degradacion, no solo crashes.
- Separa "modelo estable" de "producto estable"; no son lo mismo.
Esta noticia conversa muy bien con nuestra cobertura sobre Claude Code y sus limites reales de throughput, porque ambas dejan la misma idea: un buen modelo puede perder valor rapido si el harness y los defaults quedan mal calibrados. Y si todavía estas montando la base de sesiones, tools y memoria, el mejor punto de entrada sigue siendo Instala Tu Propio Agente de IA.
La lectura final es simple: el postmortem de Anthropic no es chisme de producto; es una guia concreta de donde mirar cuando tu agente "se siente peor" aunque el modelo siga siendo el mismo.