Amazon Bedrock rediseña su consola para APIs compatibles con OpenAI y Anthropic: donde si ahorra tiempo y donde no
AWS anuncio el 4 de junio de 2026 una consola nueva para Bedrock pensada alrededor de APIs compatibles con OpenAI y Anthropic. La mejora útil para builders no es la UI bonita: es reducir el trabajo manual entre elegir modelo, generar snippets y mover un experimento hacia producción.
Por qué importa
Esta nota se enfoca en la decisión práctica para builders: qué cambia, qué riesgo agrega y cómo aplicarlo sin romper operación.
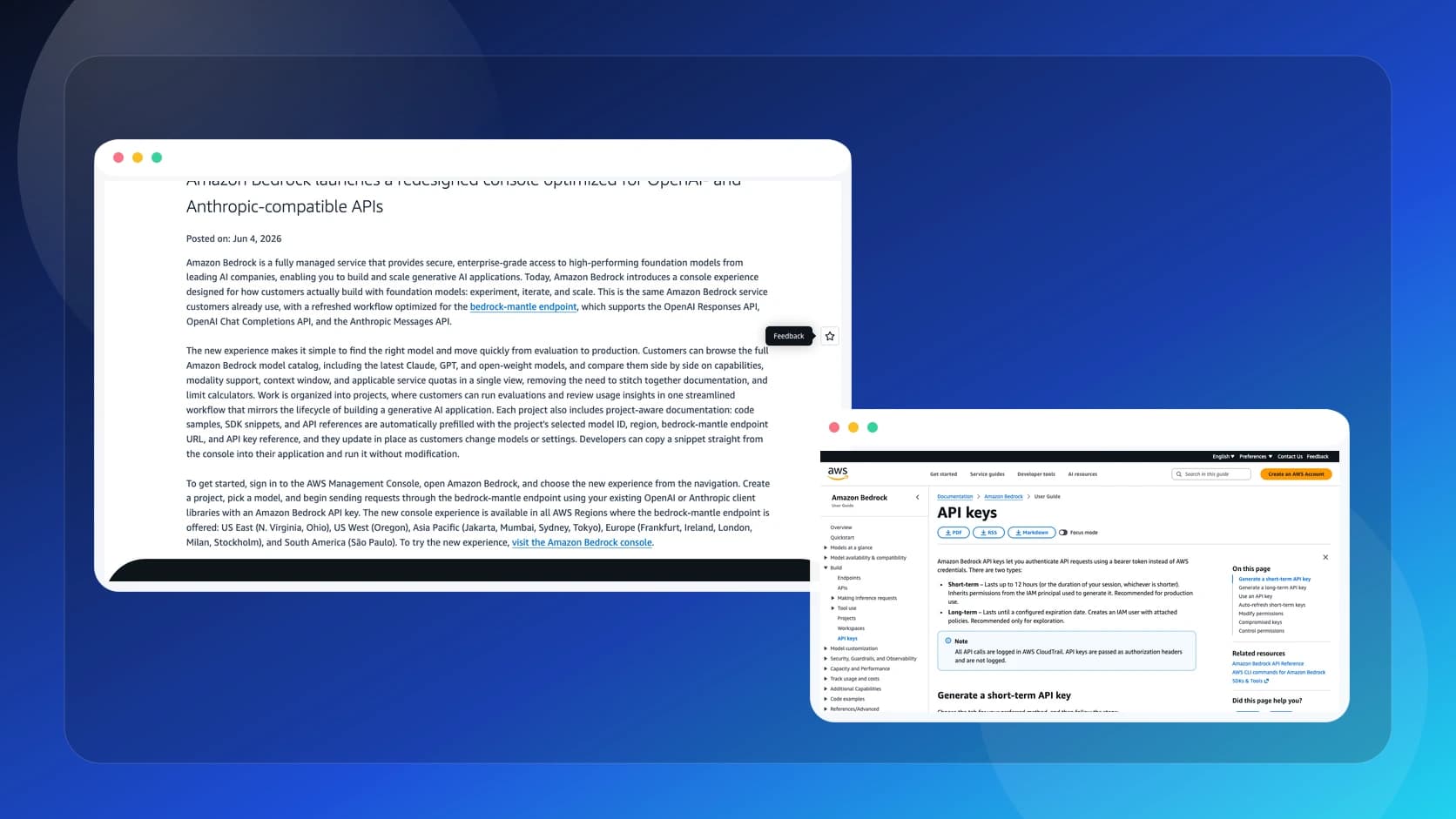
La mitad del tiempo perdido al probar modelos no se va en inferencia. Se va en la friccion entre pantallas, credenciales, snippets rotos y tablas separadas para entender que endpoint, que cuota y que modelo tocan en cada region. Por eso el anuncio de Amazon Bedrock del 4 de junio de 2026 merece más atencion que la que suele recibir una "nueva consola".
AWS no cambió el servicio. Cambio el flujo. La nueva experiencia de Bedrock esta organizada para gente que ya trabaja con APIs compatibles con OpenAI y Anthropic y quiere pasar de prueba a implementacion sin rearmar medio contexto a mano.
Lo que realmente cambia
La nota oficial aterriza cuatro cambios concretos:
- la consola gira alrededor del endpoint bedrock-mantle;
- ese endpoint soporta OpenAI Responses API, OpenAI Chat Completions API y Anthropic Messages API;
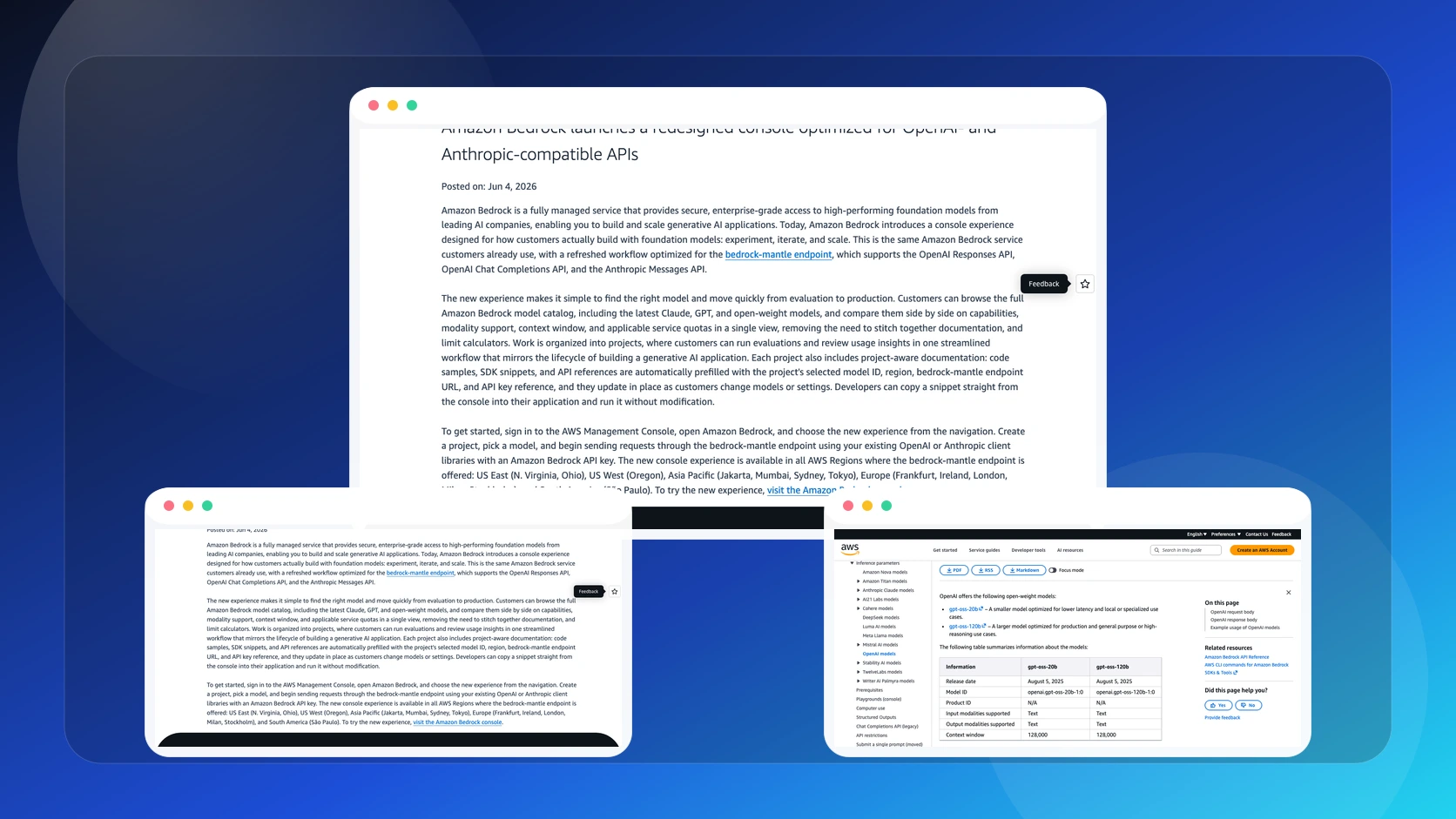
- los modelos se comparan en una sola vista con capabilities, modalidades, context window y quotas;
- y el trabajo se organiza por projects con evaluaciones, usage insights y snippets ya rellenados con el modelo, la region y la referencia de API key.
Ese último punto es el más útil para builders. AWS dice que los ejemplos y referencias se prefill automaticamente con el model ID, la region, la URL del endpoint y la referencia de la llave. Si eso se cumple bien en la práctica, quita una parte muy común del error tonto: copiar un ejemplo correcto para el modelo equivocado o para la region incorrecta.
Donde si puede ahorrar tiempo
Yo veo valor claro en tres escenarios.
El primero es el equipo que ya usa clientes de OpenAI o Anthropic y no quiere reescribir demasiado solo para probar Bedrock. La documentacion de AWS deja claro que puedes autenticarte con Bearer tokens y que, en varios casos, el camino recomendado pasa por Amazon Bedrock API keys en vez de credenciales AWS tradicionales. Eso acerca bastante la experiencia al contrato de clientes que ya conoces.
El segundo es el equipo que compara modelos seguido. La nueva vista lado a lado reduce una tarea poco glamorosa pero recurrente: saltar entre docs, quotas y tablas solo para responder "este modelo soporta esto en esta region?".
El tercero es el equipo que necesita dejar trazabilidad desde temprano. Los projects con evaluaciones y usage insights en el mismo loop son más valiosos que otra galeria de demos si lo tuyo no es jugar, sino justificar una decision técnica.
Donde no conviene exagerar
Tampoco compraria la narrativa de que una consola nueva resuelve el problema de plataforma.
Primero, porque compatibilidad de API no significa equivalencia operativa total. La doc de Bedrock para modelos OpenAI sigue marcando detalles propios: autenticacion con API key de Bedrock, mapeos de campos cuando usas Converse, y diferencias sobre como aparecen ciertas salidas o headers.
Segundo, porque una vista mejor no reemplaza gobernanza. La misma documentacion de AWS subraya que:
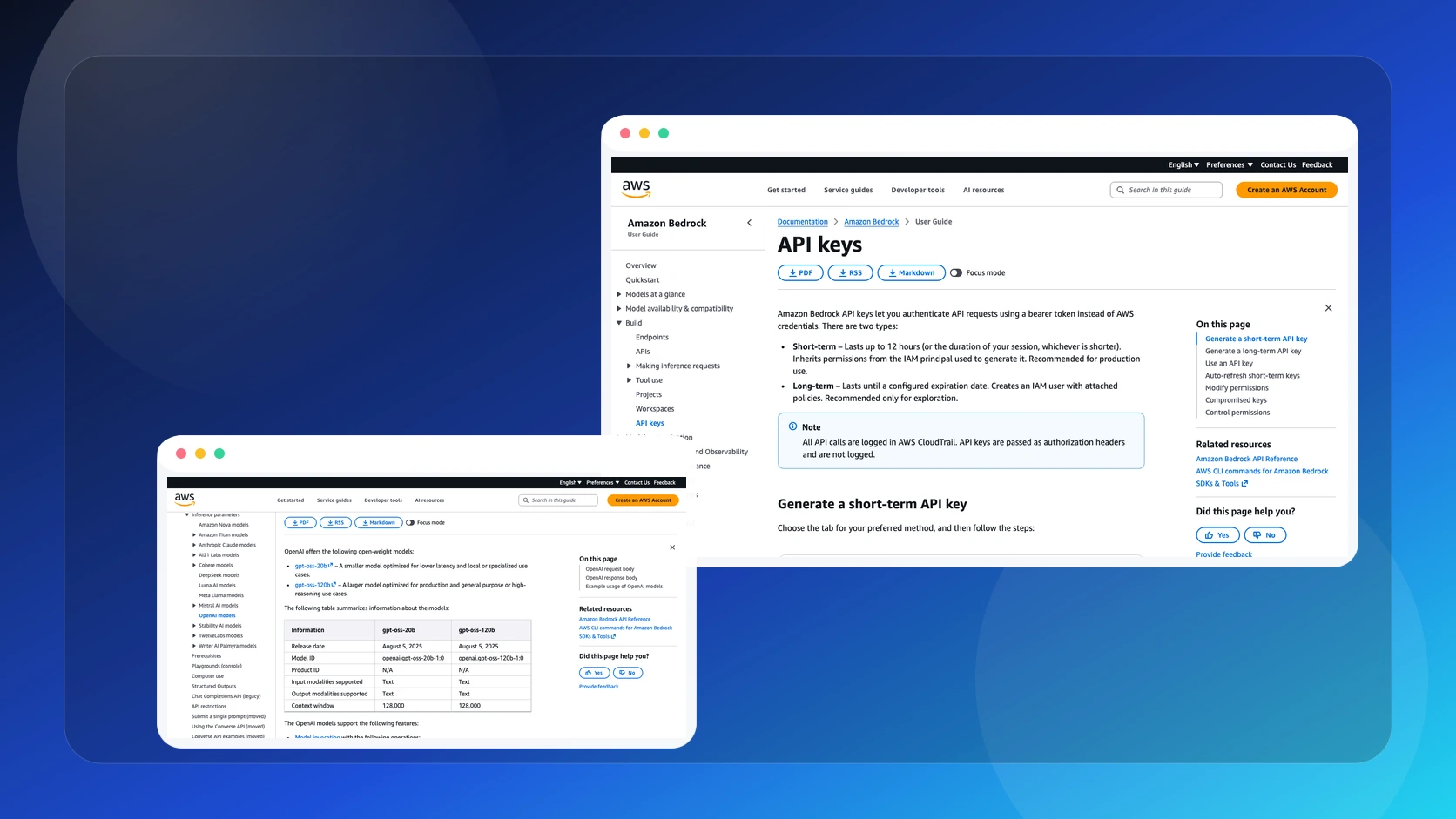
- las llamadas quedan registradas en CloudTrail;
- hay diferencia entre short-term y long-term API keys;
- y para producción se recomiendan llaves cortas heredando permisos del principal IAM.
Eso significa que la parte importante sigue siendo la misma: quien puede generar la llave, con que permisos, por cuanto tiempo y para que workload.
Mi checklist rapido
Si estas evaluando este lanzamiento, yo haria estas preguntas antes de entusiasmarme:
- Tu equipo ya usa SDKs o clientes compatibles con OpenAI o Anthropic y quiere mantener ese contrato?
- Comparas modelos por region, cuota y contexto con suficiente frecuencia como para que la consola actual ya te estorbe?
- Necesitas una capa de evaluación y trazabilidad desde el mismo lugar donde pruebas?
- Tienes claro como vas a gobernar las API keys de Bedrock y no solo como vas a copiarlas?
Si la mayoria te sale en "si", este release vale la pena mirar.
Por que tiene demanda cualificada
La demanda aquí no depende de inventar volumen. Sale de una necesidad ya visible en el mercado: equipos que quieren usar modelos frontier sin rehacer todos sus clientes ni abrir otra isla de gobernanza. Cuando AWS pone nombres concretos como Responses API, Chat Completions API, Anthropic Messages API y bearer tokens dentro de Bedrock, esta capturando una intención de implementacion muy clara.
Por eso esta nota conversa bien con OpenAI y Codex dentro de AWS: una explica la llegada del proveedor y la otra baja el costo operativo del día a día cuando ya estas comparando, evaluando y copiando snippets sobre Bedrock. Si todavía te falta una base antes de entrar a estas capas de plataforma, el punto de entrada sano sigue siendo Instala Tu Propio Agente de IA.
Mi lectura
La noticia no es "AWS mejoro la interfaz". La noticia es que Bedrock empieza a admitir de forma más sería que muchos builders ya piensan y programan en contratos estilo OpenAI o Anthropic, y les quiere reducir el costo de aterrizar eso dentro del perímetro AWS.
No resuelve seguridad, permisos ni criterio de evaluación. Pero si reduce bastante una friccion real: la distancia entre probar un modelo y tener un camino limpio para llevarlo a codigo útil.